- MACH
API Calls: Everything You Need to Know About It

In today's interconnected world of software development, there's a term you'll often hear thrown around: API calls. It's a concept that's become essential to modern-day software development, but what exactly are API calls?
Simply put, an API (Application Programming Interface) call is a way for two different software systems to communicate with each other over the Internet. This communication involves sending requests and receiving responses in a structured format that both systems can understand. It's like a language that allows one software system to "speak" to another system, making it possible to retrieve and share data.
API calls play a crucial role in modern software development, enabling products to interact with external systems, providing access to third-party services, and facilitating the integration of software components. By leveraging these interactions, developers can make software that is more flexible, scalable, and efficient.
In this article, we're going to take a deep dive into the world of API calls. We'll explore:
how to make API calls
how to use APIs to build software systems
we'll give you a detailed explanation of the building blocks that make up an API
We'll also look at some real-world examples of how API calls are being used, and we'll provide some tips and best practices for using APIs in your own software development endeavors.
Networking
The Internet is a complex network comprising various protocols, end systems, and layers, making it intricate to comprehend. However, we can consider an essential question to help break it down: Can any organized network architecture handle this complexity?
The answer is an affirmative yes. That's the power of organizing, and it's precisely what's achieved through the layered architecture of the internet.
Before discussing API calls in detail, let’s start with some fundamental concepts.
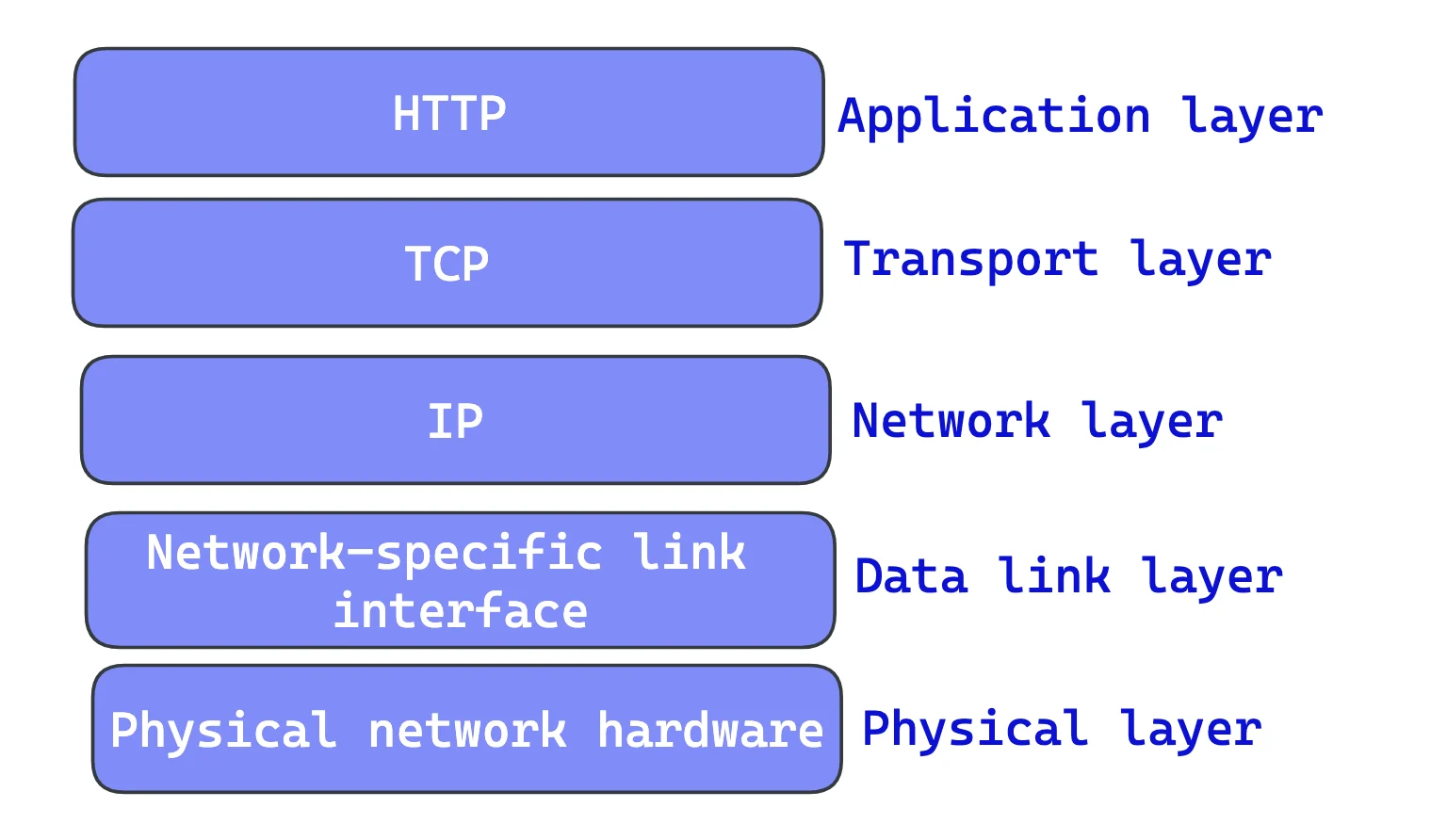
Layered Protocol Stack
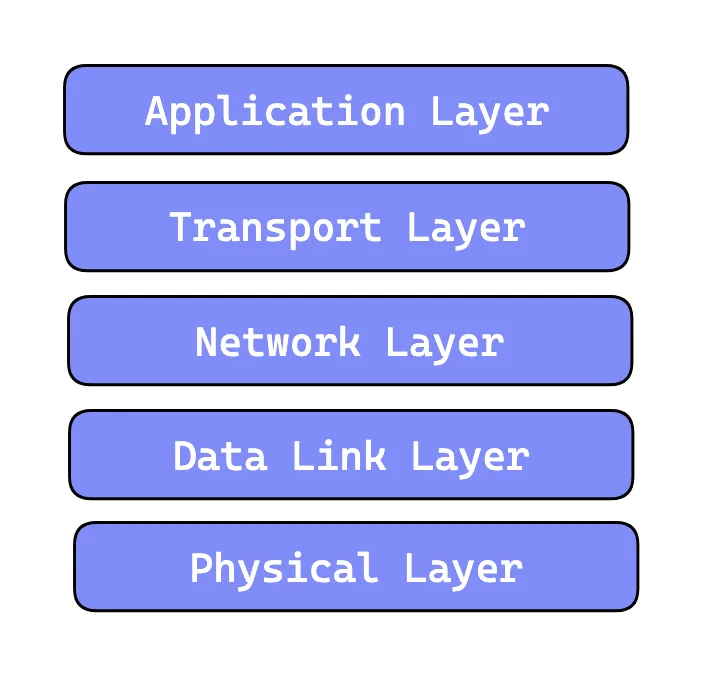
To understand network application communication, it's essential to start at the application layer, where end systems exchange data.
At this layer, communication between applications occurs using API calls. However, deploying an API call is not as simple as two applications sending messages to each other haphazardly; there needs to be a set of standardizations.
Asking specific questions, such as how messages are structured or what the meaning of various fields in messages is, delves us into the application-layer protocol.
The application-layer protocol defines the rules for communication between applications, including the message structure and the allowed messaging parameters. Application-layer protocol defines[2]:
The types of messages exchanged, for example, request messages and response messages
The syntax of the various message types, such as the fields in the message and how the fields are delineated
The semantics of the fields, that is, the meaning of the information in the fields
Rules for determining when and how a process sends messages and responds to messages
For example, HTTP(the HyperText Transfer Protocol [RFC 2616]) is an application layer protocol. It defines the format and sequence of messages exchanged between the different applications.
As another example, let’s consider e-mail application. It uses SMTP (Simple Mail Transfer Protocol) [RFC 5321]. It defines how messages are passed between servers, how messages are passed between servers and mail clients, and how the contents of message headers are to be interpreted[3].
There are also different application-layer protocols besides these;
FTP (File Transfer Protocol) - used for transferring files between computers on a network.
POP3 (Post Office Protocol version 3) - used for retrieving email messages from a server.
IMAP (Internet Message Access Protocol) - is used for accessing and managing email messages on a server.
DNS (Domain Name System) - used for resolving domain names into IP addresses.
SNMP (Simple Network Management Protocol) - is used for managing and monitoring network devices.
DHCP (Dynamic Host Configuration Protocol) - used for assigning IP addresses and other network configuration information to devices on a network.
SSH (Secure Shell) - used for secure remote access and file transfer over the internet.
Telnet - used for remote access to a command line interface on a networked device.
AMQP(Advanced Message Queuing Protocol) - is used for reliable message-oriented communication between applications and is used for queuing, routing, and messaging between networked systems.
Binary Protocol - is used for optimized efficiency and performance by using the binary format to represent data.
All of these protocols serve different purposes.
APIs unlock data and allow you to connect systems, applications, devices, and datasets. Therefore, when designing your API, it is critical to choose an architectural style that best supports the intended use of the API, depending on the required functional capabilities.
You can choose REST, RPC, streaming, etc., as your preferred style of architecture. The choice should depend on your project’s needs. Based on your chosen architecture, your API will communicate with other applications asynchronously or synchronously using a viable protocol.
What Is an API Call?
The API call is basically a request made by one application to another to retrieve or manipulate data. With API, applications can communicate with each other by exchanging data and functionality.
When the application wants to access data or functionality provided by another application’s API, it makes a request to the API by sending the message over the internet using a protocol like HTTP. In return, the service responds back in specific formats like JSON or XML.
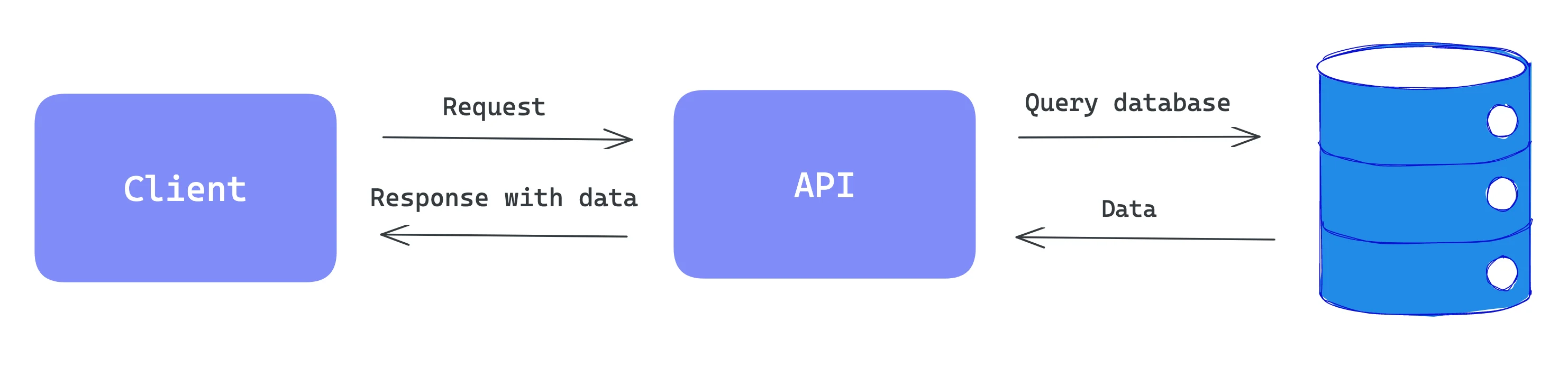
We will discuss API calls by basing on HTTP protocol. Therefore, in the first place, it is beneficial to understand HTTP.
What Is HTTP?
HTTP is an application layer protocol. HTTP doesn’t worry about the nitty-gritty details of network communication; instead, it leaves the details of networking to TCP/IP, the popular, reliable Internet transport protocol[4]. HTTP itself is not reliable. It uses the most famous reliable data transmission protocol, TCP, to guarantee data is not damaged or scrambled in transit. Once a TCP connection is established, messages exchanged between the client and server computers will never be lost, damaged, or received out of order[5].
Again, think about Layered Protocol Stack. In networking terms, the HTTP protocol is layered over TCP. HTTP uses TCP to transport its message data. Likewise, TCP is layered over IP.
Before an HTTP client sends a message to a server, it needs to establish TCP/IP connection between the client and server using IP(Internet Protocol) addresses and port numbers. Thanks to this connection, you don't have to worry about HTTP communication being destroyed, duplicated, or distorted in transit; therefore, you can focus on the details of your application.
HTTP is implemented in two programs: a client and a server. These two application talk to each other by exchanging HTTP messages. HTTP defines the structure of these messages and how the client and server exchange messages.

What kind of messages are we talking about here? Let’s quench our thirst for curiosity about the structure of HTTP messages.
HTTP Messages
If HTTP is the Internet’s courier, HTTP messages are the packages it uses to move things around[6]. In this article, we will examine how to create HTTP messages and how to understand them.
Message Syntax
All HTTP messages fall into two types: request messages and response messages. While request messages request an action from the server, response messages carry the results of a request back to the client.
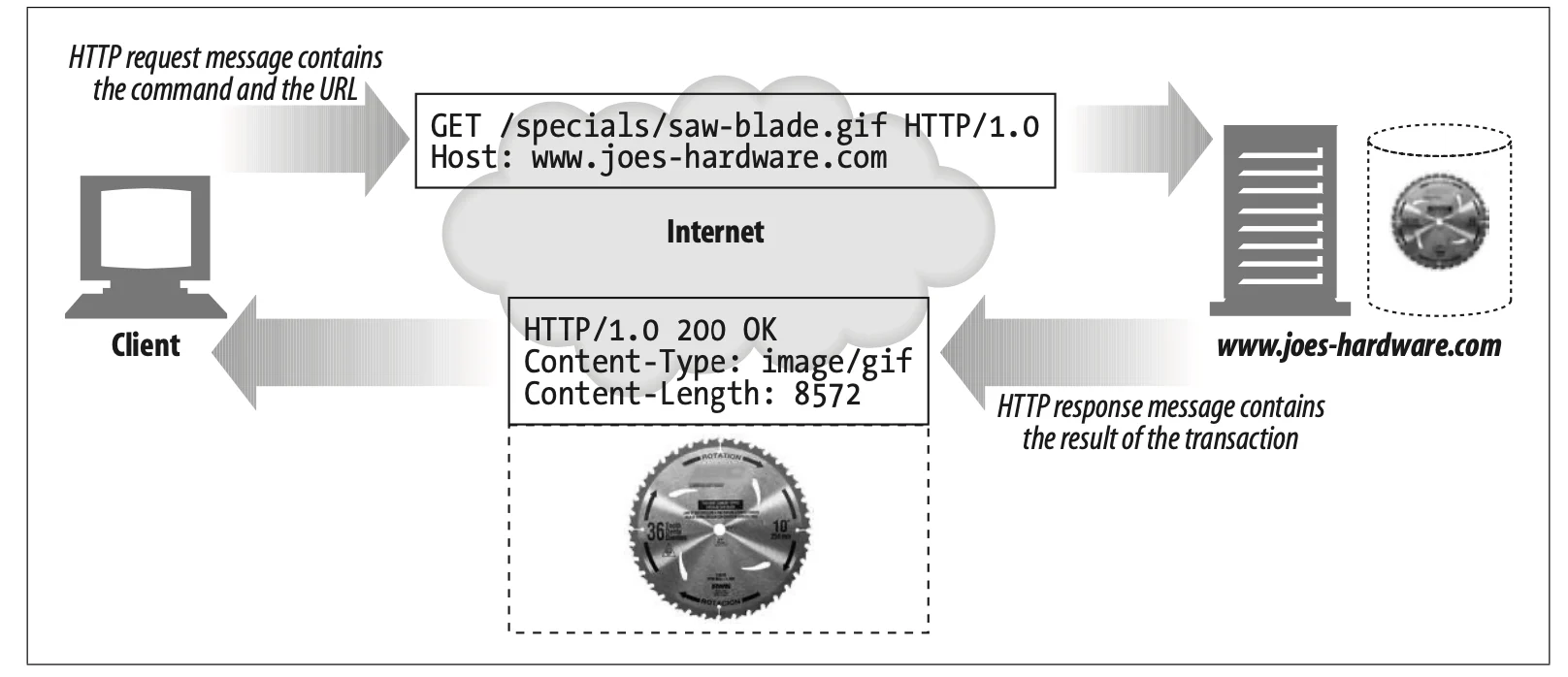
Image Source: HTTP: The Definitive Guide
Let’s look at close parts of HTTP messages:
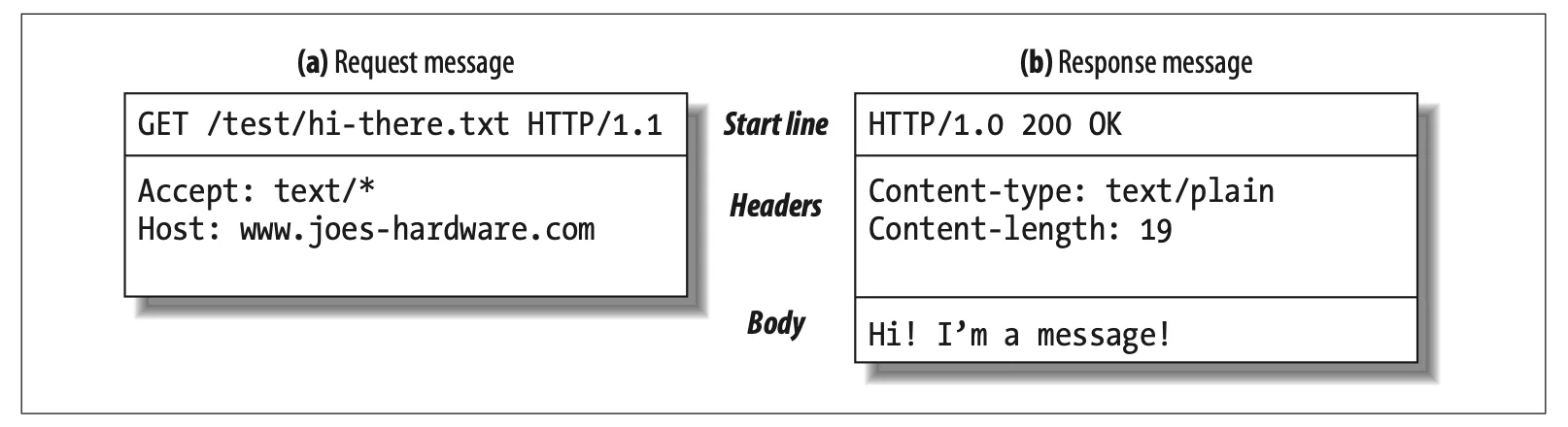
Start Lines
All HTTP messages begin with a start line. The start line for a request message says what to do. The start line for a response message says what happened[7].
Request Line: Request messages ask servers to do something to the resource. This is why it should start with a method describing the server's operation. If the client wants to ask the server to do something to the resource, the resource also should be described with the request URL. In addition, the request line includes an HTTP version.

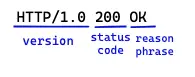
Response Line: Response messages carry status information and any resulting data from an operation back to a client[8]. Response lines include the HTTP version, numeric status code, and a textual reason phrase. With the status code and textual reason phrase, clients can understand the status of their request.
HTTP Methods
Request messages ask servers to do something to a resource. It is a single word like GET, DELETE, or POST. It describes what operation the server should perform.
For example, in the figure above, in the line “GET /specials/saw-blade.gif HTTP/1.0,” the method is GET.
The HTTP specifications have defined a set of common request methods:

Image Source: HTTP: The Definitive Guide
As you can see, these methods are used for different purposes. In addition, some methods have a body in the request message, and others have nobody. This provides common ground for the developers while they are designing their API.
Even if all these methods can be implemented in any server, some restrictions can be beneficial while you are designing your API. For example, you may not want to let someone delete or modify your resources. You need to be careful about the unsafe method.
What do we mean by unsafe methods?
HTTP defines a set of methods that are called safe methods, which are GET, HEAD, or OPTIONS. Safe means that no action should occur due to an HTTP request. These methods do not modify the resources. The important point in safe methods is that the client doesn't request any server change itself and, therefore, won't create an unnecessary load or burden for the server. Browsers can call safe methods without fearing causing any harm to the server; this allows them to perform activities like pre-fetching without risk[9].
GET: It is the most common method. it is used to ask the server to send a resource. It reads documents from a server.
HEAD: It is similar to the GET method, but when you send a request to the server with the HEAD method, it returns only the headers in the response. Nobody returned the response message. It provides you to inspect the headers for resources without actually getting resources. In this way, you can learn if a resource exists, the type of resource, or whether it is modified.
PUT: Unlike the GET method, The PUT method writes documents to a server. It semantically takes a body of requests. It is used to create a new document named by request URL. If it already exists, use the body to replace it.
POST: It submits an entity to the specified resource, often causing a change in state or side effects on the server. It is usually used to send data to a server to create/update a resource.
TRACE: When a client makes a request, that request may have to travel through firewalls, proxies, gateways, or other applications. Each of these has the opportunity to modify the original HTTP request. The TRACE method allows clients to see how their request looks when it finally makes it to the server[10]. The main purpose is to verify that requests are going through the request/response chain as intended.
OPTIONS: It is used to ask the server about the various supported capabilities of the web server. You can ask a server about what methods it supports in general or for particular resources.
DELETE: It is used to ask the server to delete the resources specified by the request URL.
Request URL
URLs are basically standardized names for Internet resources. URLs address pieces of electronic information, telling you where they are located and how to interact with them. Therefore, it provides means for applications to be aware of how to access a resource. Therefore, the request URL describes the resource on which to perform the method.
Version
It is the version of HTTP that the message is using. It tells the server what dialect of HTTP the client is speaking.
HTTP/<major>.<minor>
You can find version numbers in both request and response message start lines. Client and server inform each other what version of the protocol they conform to.
Version numbers are intended to provide applications speaking HTTP with a clue about each other’s capabilities and the format of the message. An HTTP Version 1.2 application communicating with an HTTP Version 1.1 application should know that it should not use any new 1.2 features, as they likely are not implemented by the application speaking the older version of the protocol[11].
Status Code
It describes what happened during the request. It is a three-digit number, and the first digit of each code describes the general status of the code(success, error, etc.). It is an easy way for clients to understand the result of their transactions.
Many things can happen when the client sends request messages to an HTTP server. If you are on your best day, the request will complete successfully. However, if you are in the unlucky day, the resource you requested could not be found, or you do have no permission to access the resource.
In the example of HTTP messages, you can see that the status code is returned in the start line of each response message as both numeric and human-readable status.
As mentioned, status codes are grouped by their first digit :
100 - 199(Informational): The server has received the request and is continuing the process
200 - 299(Success): The request was successful.
300 - 399(Redirection): The resource has been moved. You have been redirected, and the completion of the request requires further action.
400 - 499(Client Error): The client did something wrong in the request.
500 - 599(Server Error): Something went wrong on the server side.
You can check the detailed status codes figure below:

Status codes should be used for your purpose. While you are designing your API, you need to be careful about which status code you will use in specific situations.
Reason-Phrase
It is the human-readable version of the status code. It provides a textual explanation of the status code.
For example, if the server returns ‘HTTP/1.0 200 OK’, the reason phrase is ‘OK’
Thanks to reason-phrase, you can pass it along to your users to indicate what happened during the request.
Headers
The start line can have multiple header fields. HTTP headers are used for adding additional information to request and response messages. They are basically just lists of name/value pairs.
Let’s look at some examples:
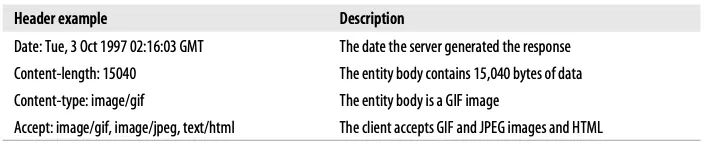
Listing all of the possible variations of HTTP headers is nearly impossible. However, the important point is important to know the HTTP header provides to pass additional context and metadata about the request or response. Headers and methods work together to determine what clients and servers do.
Entity Body
You can think of HTTP messages as the crates of the Internet Shipping System, then HTTP entities are the actual cargo of the messages[12].
The entity-body includes raw cargo. If you need any other descriptive information, they are contained in the headers. Because the entity-body is just raw data, the entity-headers are needed to describe the meaning of that data. For example, While the Content-Type entity header tells you to type raw data, Content-Length tells you the message body size in bytes.
The body is an optional part of HTTP messages. Entity bodies are the payload of HTTP messages. They are the things that HTTP was designed to transport. Different kinds of data can be carried by HTTP messages, such as images, videos, HTML documents, etc.
How to Make an API Call
That's enough theory, don't you think? Let’s see examples of API calls. We will use Postman, a very useful tool to create APIs, and JSON Placeholder, a free fake API.
Let’s see some examples of making API calls via Postman:
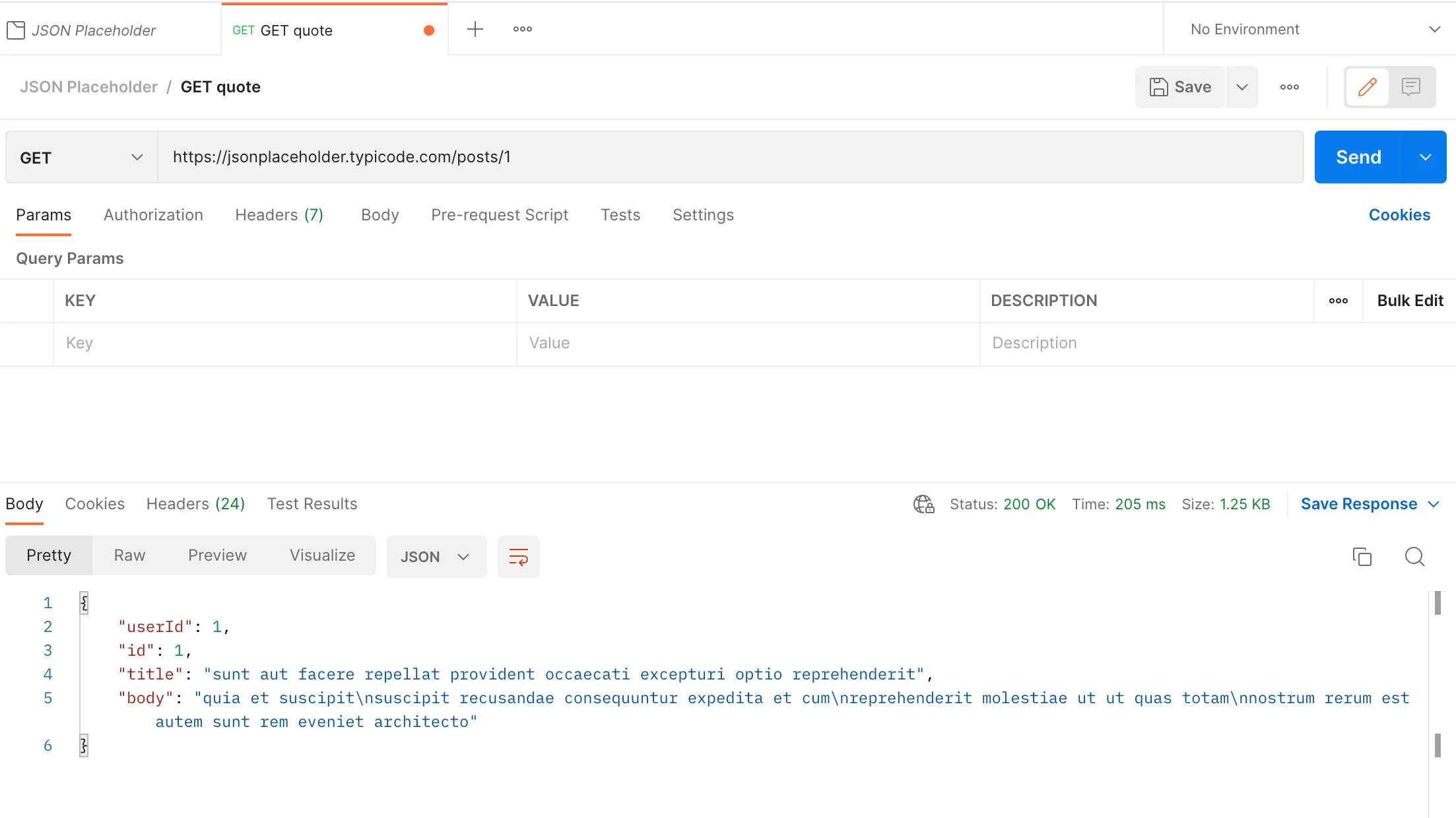
GET
To get a resource whose id equals 1:
To list all resources:
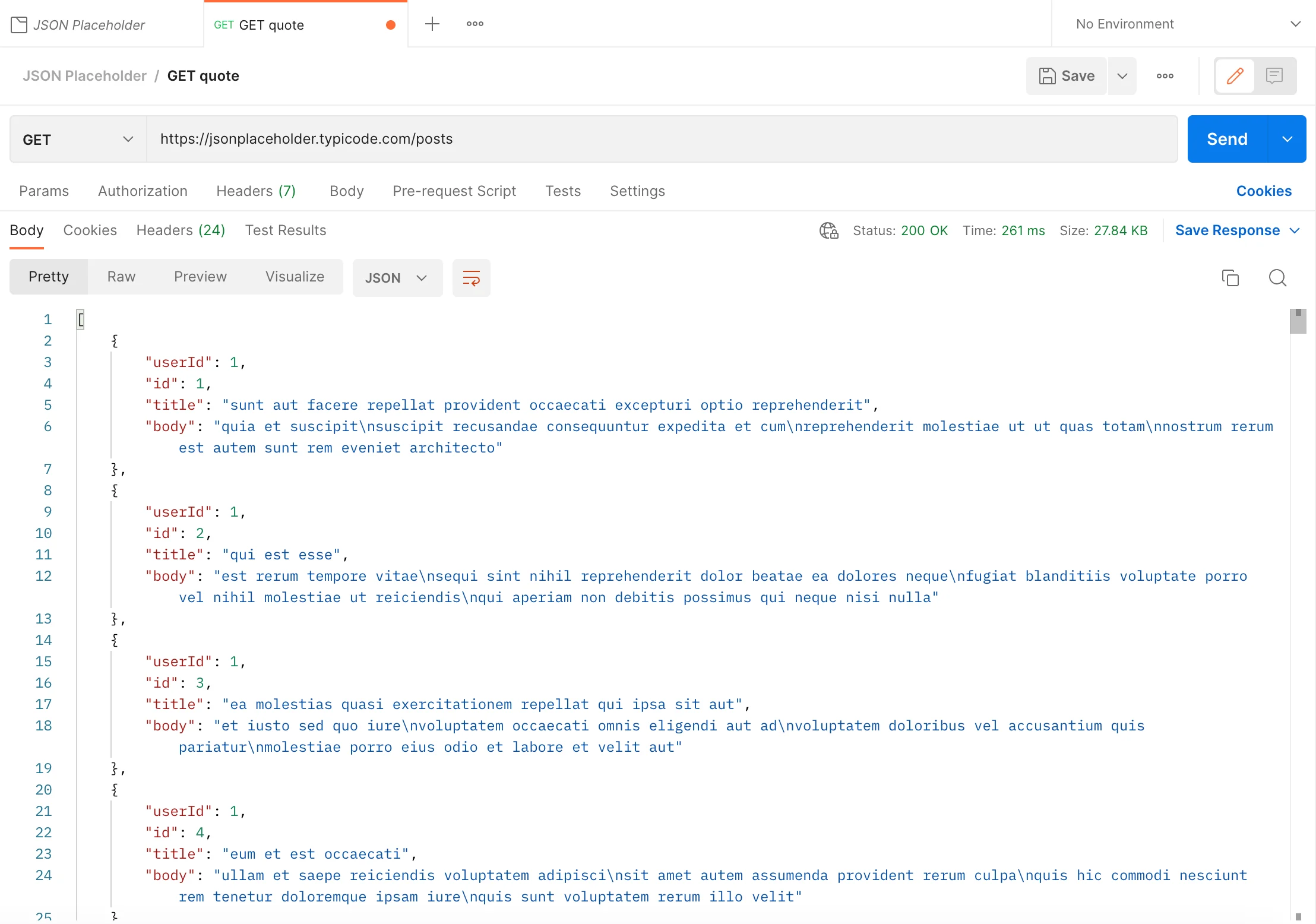
Because these two fetching transactions are successful, the status code is OK(200).
POST
To create a new resource:
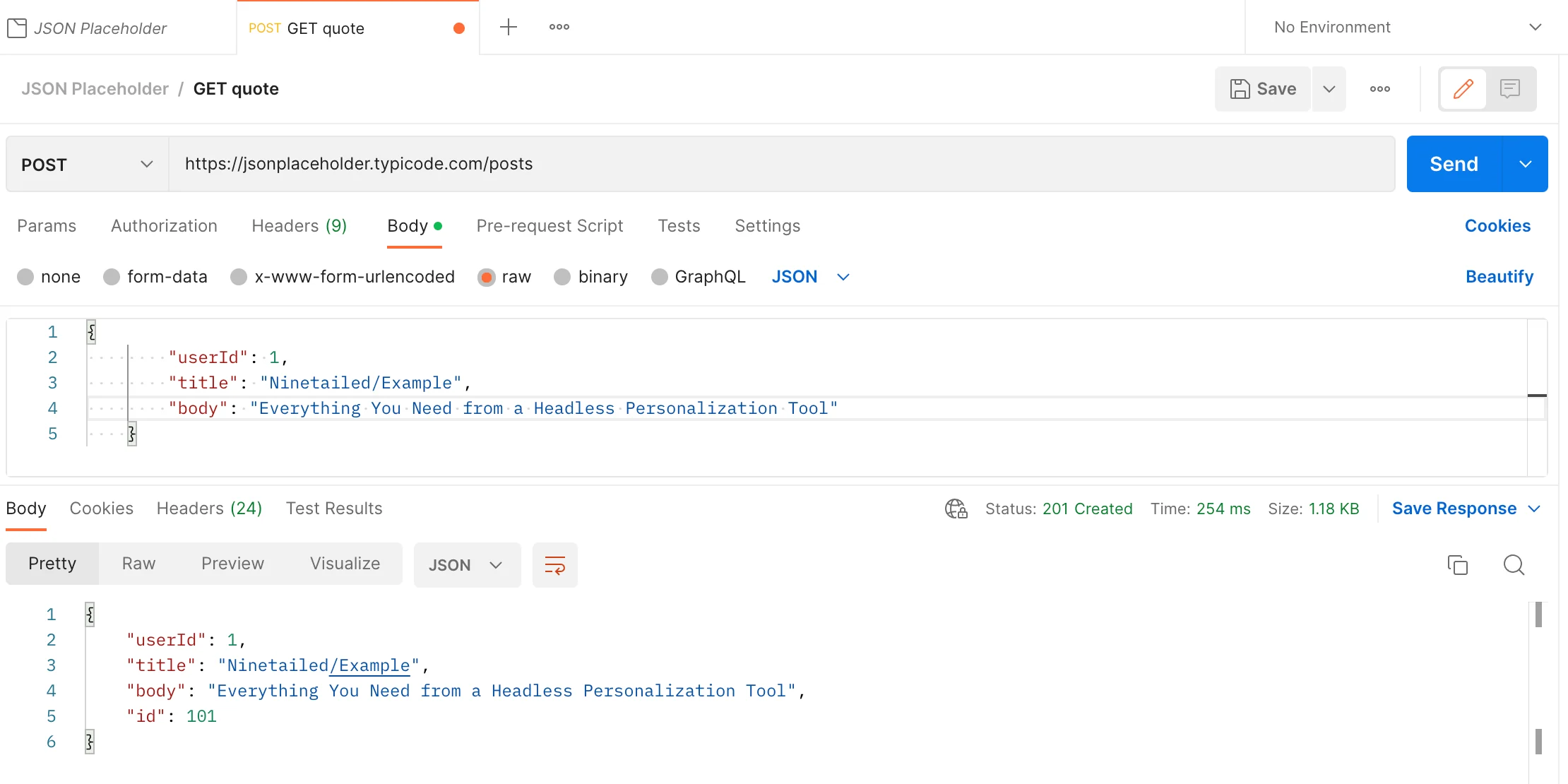
As you can see, when we create a new resource, our fake API returns an HTTP message. The message body includes creating a new resource with a new id. Because the transaction is successful, it returns a response with status code 201(Created).
However, because it is a fake API, resources will not be really updated on the server. Therefore, when you want to get a resource whose id equals 101, it will return an empty JSON.
PUT
To update resources:
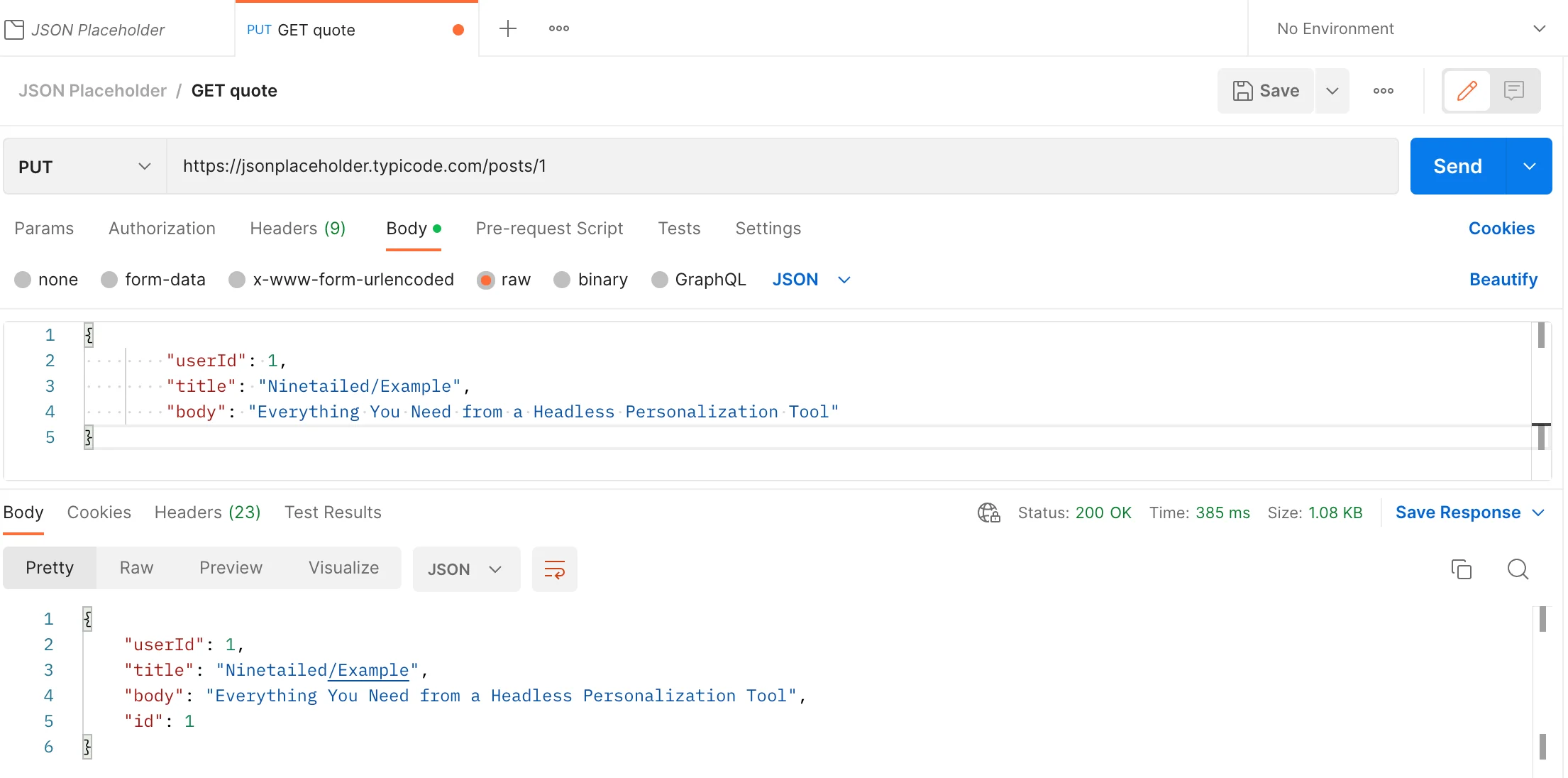
When we update resources, fake API returns an HTTP message. The message body includes updated resources. Because the transaction is successful, it returns a response with status code 200(OK).
However, because it is a fake API, resources will not be really updated on the server. Therefore, when you want to get a resource whose id equals 1, it will return an unchanged version of the resource.
DELETE
To delete resources:
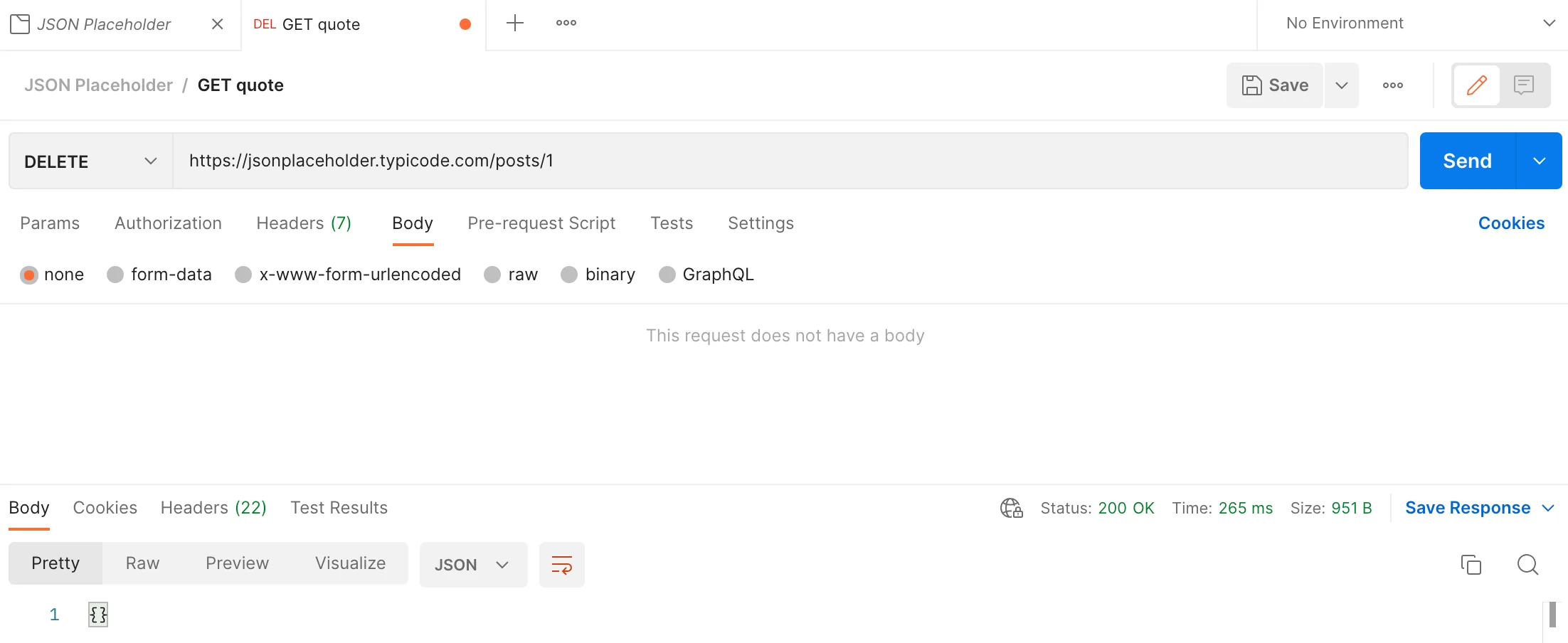
When you delete a resource with id 1, the fake API returns an HTTP message without a body and a 200(OK) Status Code. However, because it is a fake API, resources will not be really deleted on the server.
Did anything catch your eye while you were doing all this?
JSON Placeholder doesn't allow you to update resources. As mentioned before, because DELETE, PUT, and POST are not safe methods, it makes you feel like you are using these methods.
Another point is the request URL. Because this fake API is designed in RESTful style, these endpoints are also incompatible with REST standards. You can check our previous article about REST API to get more information.
How to Secure APIs from Invalid API Calls
A book could be written on designing secure APIs, and it has been. There are a lot of points you need to consider if you aim to design secure APIs. It is impossible to cover all in just one article’s section.
In this article, we basically mention three techniques.
Rate limiting
Authentication & Authorization
Necessary Information in Response
Rate Limiting
In that context, let me introduce you to the concept of rate limiting. Rate limiting is important for maintaining system security, stability, and fairness.
if you’re building an API for public use, then it’s quite likely that you’ll want to implement some form of rate limiting to prevent clients from making too many requests too quickly, and putting excessive strain on your server[13].
All your clients won’t be an angel. Some can try to down your system by sending too many requests. In addition, these people can try to guess passwords by submitting many different combinations of characters. Limiting the number of login attempts in a certain period reduces the possibility of win of these attackers.
With rate limiting, you prevent system overloaded, abuse, or unauthorized access by limiting the number of requests in a certain period of time.
You can use middleware to help with implementing rate limiting. You can use this middleware to check how many requests have been received in the last ‘N’ seconds,, and if there have been too many, it should send the client a 429(Too Many Request) HTTP Status Code.
Rate-limiting techniques can differ according to your needs.
Global Rate Limiting
It considers all the requests that your API receives rather than separate rate limiters for every individual client.
Suppose you have A, B, and C clients, and B client is the bad guy. He tries to down your system by sending too many requests. With global rate limiting, your API sends 429(Too Many Request)Code to your innocent A and C clients. It considers all requests coming from regardless of who.
IP-based Rate Limiting
Using the global rate limiting can have benefits if you want to enforce a strict limit on the total rate of requests to your API. Therefore, you do not care where the requests are coming from in that manner. However, if you want one bad guy making too many requests not to affect other innocent clients, using a separate rater limiter for each client will be logical.
IP-based Rate Limiting can make your dreams come true. It is conceptually like creating an in-memory map of rate limiters, using the IP address for each client as the map key[14].
Each time a new client makes a request to your API, you can initialize a new rate limiter and add it to the map. In this way, every client has their own rate limiter.
Authentication and Authorization
Authentication and authorization are important components of a comprehensive security strategy.
While authentication is verifying a user's or application's identity, authorization is determining whether a user or an application has the necessary permission to perform a certain action or access a certain resource. Once a user has been authenticated, the application can determine what actions they are authorized to perform.
In practice, authentication and authorization are often used in conjunction with rate limiting to provide a more comprehensive security solution.
For example, you have an online shopping site, and you want to prevent fraudulent purchases. You can implement a combination of authentication, authorization, and rate limiting to achieve this aim.
First, you can ask customers to authenticate by creating an account and providing a valid payment method. This helps your application verify customers' identity and valid means of payment.
Second, you can use authorization to control what actions the customer is allowed to perform. For example, on your site, there are two types of users: seller and customer. They see different product details pages. While sellers see that page as a draft, customers see it as the latest version of this page after publishing. While sellers can create new products with their details by filling necessary information to sell, customers can only display that product after it is published. They are allowed to perform different actions depending on their user type.
Finally, you can use rate limiting to prevent fraudulent purchases by limiting the number of purchases that can be made in a certain time period. You can use IP-based rate limiting, which can help you prevent automated bots or other malicious factors from making too many requests to purchase in a short period.
Necessary Information in Response
It is possible for an API response to expose some information bad guys can use. You don't want to send sensitive information which should not be disclosed to unauthorized parties.
For example, if your application returns an error message that contains details about your application’s internal structure or implementation, these bad guys could use this sensitive information to attack your application. Let’s make our bay guy’s stories scarier… If you return your database model as it is, these guys could use this model to get sensitive information, impersonate the user, and gain access to sensitive resources. This is one reason why developers use DTO (Data Transfer Object). It is used to encapsulate data and transfer data from one application to another. With DTO, you can limit what information you share while you send back the response to the client.
Wow, what a movie scenario!
Therefore, as a developer, you can use encryption to protect sensitive data in transit, minimize the amount of information included in error messages, and properly validate user input to prevent injection attacks. Don’t forget you need to be careful while designing your API!
The Bottom Line
The layered protocol stack is a fundamental concept in computer networking that organizes network protocols into distinct layers, each with specific roles. The Application Layer protocol, HTTP, allows data transfer over the internet, and different applications communicate with one another via API calls, providing a means to interact with an application through HTTP and access resources and services provided by it.
To ensure secure APIs, it is essential to design them with appropriate measures, such as rate limiting, which limits the number of requests a user can make within a certain time period. This not only helps prevent abuse but also makes resource usage more efficient. Additionally, authentication and authorization play a significant role in securing your application by verifying the user's identity and ensuring that they have the required permission to access certain features and resources.
When opening your application to the world, you make it more engaging and interactive, but you need to remain cautious about potential security risks that come along with allowing others to use it. You need to take appropriate measures to ensure that your application remains secure and is not compromised by malicious actors.
Learn everything you need to know about MACH architecture