- MACH,
- JAMstack
GraphQL vs. REST API: The Ultimate Comparison


Microservices, monoliths, even miniservices, yes, services are everywhere.
We must extract, transform, and move data from one to another. In order to do this, these different kinds of services must communicate with each other.
There are many communication techniques, such as WebSocket, gRPC, AMQP, Kafka, Nats, etc.
In this article, we’ll closely look at two separate popular technologies, REST API and GraphQL, which are a type of synchronous communication patterns.
Request-Response Pattern
Before going into detail about what is Rest API and GraphQL and the differences between them, first, I want to explain what the Request-Response Pattern is.
You can think of REST API, and GraphQL is an implementation of the request-response pattern.
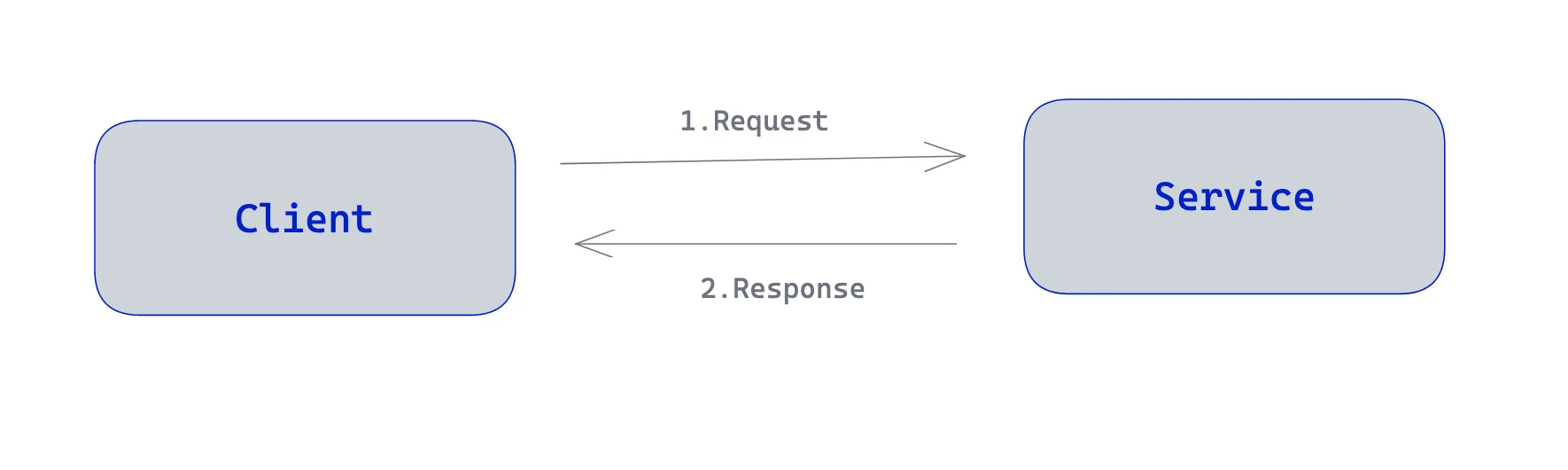
In the request-response pattern, one service (which acts as the client) sends a request and waits for a response from one or more other microservices or systems. The business logic of the client application blocks until it receives the response, and the communication channel has to be kept open until the client application receives the response.
Most implementations of the Request-Response pattern leverage protocols such as HTTP while using different data representations and exchange techniques to transfer data between services.
REST API
What Is REST API?
Before introducing what REST API is, let’s explain what REST, API, and RESTful are.
REST is really a style, or way of doing things, that Roy Fielding, the creator of REST, documented to help software architects and programmers build robust, reliable, and scalable applications and APIs.
API is a simple term that is a way to open your application to the world.
An API designed according to the principles of REST is called RESTful.
Based on these definitions, we can think of REST API as an API designed principles of REST.
A key concept in REST is a resource, which typically represents a single business object, such as a Customer or Product, or a collection of business objects. REST uses the HTTP verbs for manipulating resources, which are referenced using a URL. For example, a GET request returns the representation of a resource, which is often in the form of a JSON object, although other formats, such as binary, can be used. A POST request creates a new resource, and a PUT request updates a resource[1].
The following figure shows a real-world implementation of a REST API: an Order service in an online retail application.

In this example, we have represented an Order as a resource, and all requests sent in the form of HTTP operations are executed against that entity. We can send an order-creation request by using an HTTP POST message to the order resource located at a given URL. Similarly, we can retrieve, update, or delete the order resource by sending HTTP GET, PUT, and DELETE requests, respectively.
Sometimes, when designing API as REST, it’s really hard how to map the operations you want to perform on a business object to an HTTP verb. For example, PUT is used for updating operations. When we want to cancel the order, maybe revise the order, etc., it's hard to express this behavior by using PUT. Also, an update might not be idempotent, which is a requirement for using PUT. Because of this challenge, we used to see restful endpoints, which include sub-resource like POST /orders/{orderId}/cancel, POST /orders/{orderId}/revise.
What about retrieving multiple related objects in a single request, ahh that's the hard one too. For example, the client wants to retrieve the order and the order’s consumer. A pure REST API would require the client to make at least two requests, one for Order and another for its Consumer. This has led to the increasing popularity of alternative API technologies such as GraphQL, which we will see later.
Despite these challenges, REST seems to be the de facto standard for APIs. If our business use case fits the resource-oriented model (in which you can represent business entities and functionalities such as HTTP resources and operations).
Advantages of REST API
Simple and easy-to-understand architecture. It is easy to implement and use in web applications.
Flexible and can be used with a variety of programming languages and frameworks.
Stateless means that the server does not need to keep track of the client's state, making it more resilient to failures and easier to scale.
Interoperate with disparate sets of clients (web clients, mobile clients)
Supports various content types (JSON, CSV, XML) based on client requests. It presents human-readable text-based message formats.
Supports caching, which can improve the performance of web applications by reducing the number of requests to the server.
Disadvantages of REST API
It only supports the request/response style of communication. So reduces availability. In order to communicate, the service and client must be up and running.
Clients must know the location (URLs) of the service instances. Because in the microservices era, we have lots of kinds of services, the clients must use a service discovery mechanism to locate service instances.
Fetching multiple resources in a single request is challenging.
It’s sometimes difficult to map multiple update operations to HTTP verbs.
It does not provide any inherent security mechanisms, so it is up to developers to implement security measures, such as authentication and authorization, which can be challenging.
It can be less efficient than other communication protocols (binary etc.), as it relies on the use of HTTP and XML/JSON, which can result in larger amounts of data being transferred.
As web applications built on REST evolve, it can be difficult to manage changes and updates to the API while maintaining backward compatibility for existing clients.
Overall, REST API is a widely-used and powerful architecture, but it is not without its challenges and limitations.
GraphQL
What Is GraphQL?
GraphQL is an open-source data query and manipulation language for APIs, as well as a runtime for executing those queries by using a type system defined by the server. It was developed by Facebook in 2012 and released as an open-source project in 2015.
Unlike RESTful services, GraphQL is based on the concept of sending a query as a request to the microservice. The query represents the data the client is interested in, and the service’s logic fulfills those queries with the existing data and business logic [2].
GraphQL allows clients to determine which data they want, how they want it, and in what format. This is different from RESTful services, where the client doesn’t have control over the response data that it receives. GraphQL primarily uses queries, mutations, and subscriptions as the main interaction styles with consumers and services [3].
The following figure shows how a real GraphQL service works.
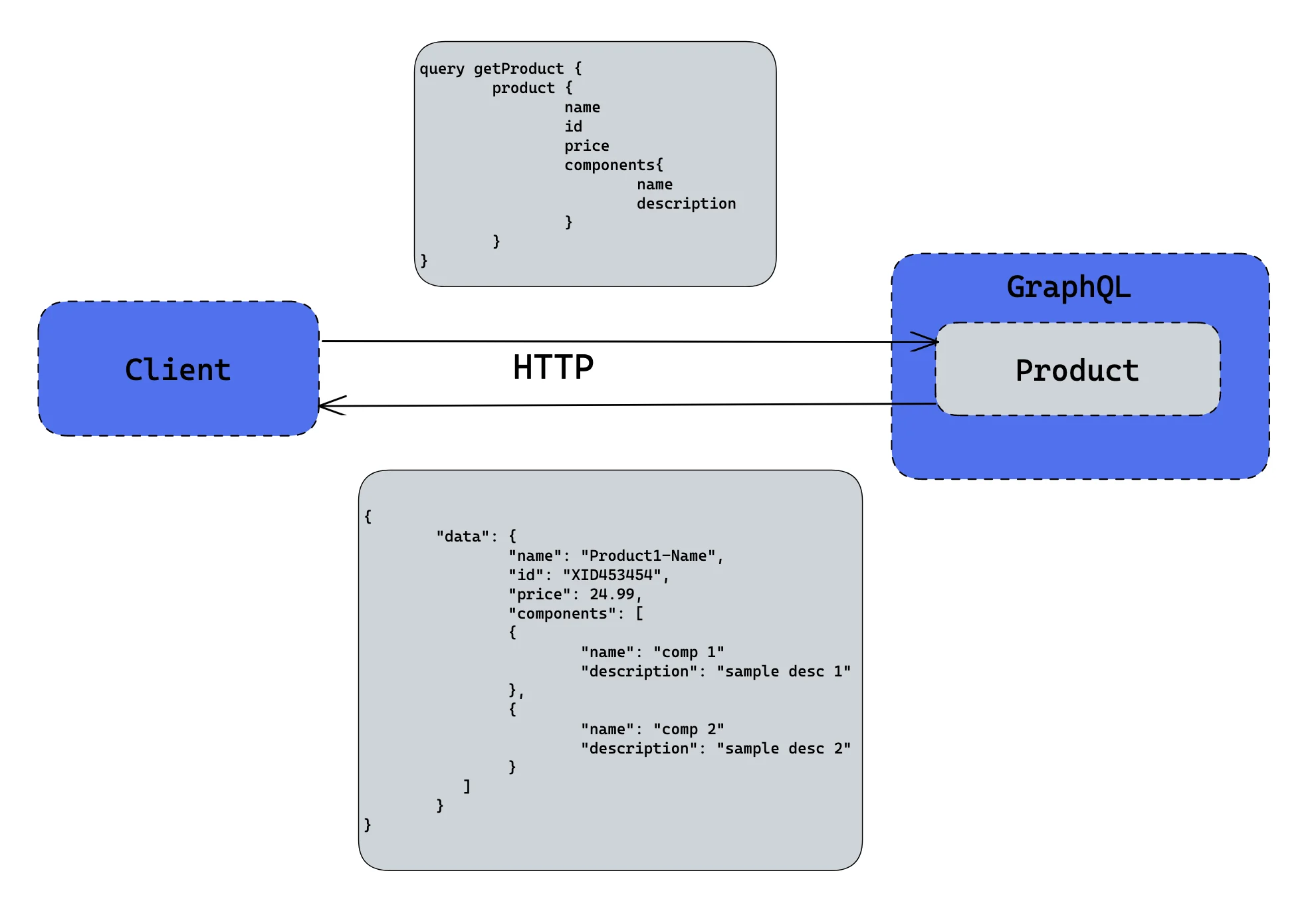
In this example, the client wants only a part of the product data; it shows this intention as a GraphQL query. Because our service implements GraphQL, it understands this intention and executes and returns only the data which the client is interested in. If the client wants to fetch more than one entity, it creates only one GraphQL query, so there is no need to make multiple requests to the service.
In comparison to REST, GraphQL offers an efficient way to fetch data without over-fetching (retrieving redundant data not required for the consumer) or under-fetching (retrieving only a portion of required data, which results in subsequent requests to fetch the remaining data). With GraphQL, the consumer can fetch the exact data needed in a single request. GraphQL provides other advantages, including validation and type checking, detailed error handling, and backward-compatible versioning[4].
Advantages of GraphQL
Clients can request only the data they need and avoid fetching unnecessary data, which can result in faster and more efficient data transfers.
Clients can use it to query data from multiple sources and APIs and can easily modify the shape and structure of the data they receive. Therefore, GraphQL reduces the number of service calls needed to retrieve business data from a service.
It allows for real-time updates through subscriptions (uses WebSocket under the hood), which can be helpful in applications that require real-time data.
It has a strong type of system that enables better tooling and documentation, making it easier for developers to understand and use APIs.
Disadvantages of GraphQL
It can simplify data fetching and manipulation in many cases but also add complexity to an application's architecture.
Implementing a GraphQL server can be more complex than implementing a REST API, especially for teams that are new to GraphQL.
It can increase efficiency in many cases but also introduce performance issues if misused, especially with large datasets.
GraphQL's syntax and concepts may take some time to learn and master, which can be a barrier to adoption for some teams.
Overall, GraphQL can be a powerful tool for building modern APIs and applications, but it is important to weigh its advantages and disadvantages carefully before deciding to use it for a particular project.
The Bottom Line: GraphQL vs. REST API
The main differences between REST API and GraphQL are:
Data fetching: In a REST API, the client has to make multiple requests to the server to fetch different pieces of data. This can result in over-fetching (getting more data than needed) or under-fetching (not getting enough data). In GraphQL, the client specifies exactly what data it needs, and the server returns only that data. This can result in fewer requests to the server and more efficient data fetching.
URL structure: In a REST API, each endpoint is represented by a URL, and the client has to know the URLs for each endpoint to access the data. In GraphQL, there is only one endpoint, and the client sends a GraphQL query that specifies the data it needs.
Data modeling: In a REST API, the server defines the data model and the endpoints that represent that data. In GraphQL, the client defines the data model and the server provides the data based on the client's query.
Caching: In a REST API, the client can cache the response for a particular endpoint to avoid making multiple requests to the server. In GraphQL, the client can cache the response for a particular query, which can include data from multiple endpoints.
Schema validation: In GraphQL, the server provides a schema that describes the data model and the operations that can be performed on that data. This can help prevent errors and provide better documentation for the API. In a REST API, there is no standard for schema validation.
In conclusion, REST API and GraphQL are ways to fetch data over the internet, but they differ in how they approach data fetching, URL structure, data modeling, caching, and schema validation.
REST API is a well-established approach that works well for many applications, while GraphQL is a newer technology that offers more flexibility and efficiency in data fetching.
Choosing between REST API and GraphQL depends on the specific needs of your application, the complexity of your data model, and the performance requirements of your application.
Learn everything you need to know about MACH architecture