- JAMstack
Publish-Subscribe Pattern: Everything You Need to Know About This Messaging Pattern


Developers constantly strive to create a dependable data flow throughout an organization's systems. The seamless integration of all data types and making it available to any service is critical.
A few years back, companies relied on transactional data, like users, products, and orders stored in tables inside a central database. However, the present technological environment is driven by a wide variety of data types that necessitate new integration methods.
Large-scale information accessibility is another obstacle that many companies face, especially when dealing with a substantial concurrent user base, frequent publication of data, and varying user interests.
The classic abstractions, such as Remote Procedure Calls (RPC), cannot handle this massive information diffusion. These approaches have an inherent scalability limit due to their tight coupling, making it imperative to use distributed solutions explicitly recommended for wide-area environments.
In this article, we will explore Messaging Systems and the Publish-Subscribe Pattern — one of the most popular messaging designs. A messaging system facilitates communication between different applications or components by transmitting messages.
The publish-subscribe pattern enables publishers to send messages to a multitude of subscribers interested in receiving those messages. Many messaging systems now have built-in support for the publish-subscribe model. By creating a mechanism for publishers to send messages to a channel and subscribers to receive messages from that channel, the publish-subscribe model is achieved with ease. For example, a messaging system like Apache Kafka is used to implement this design by allowing publishers to write messages to topics and subscribers to consume messages from these topics.
But that is not all. In this article, we’ll also delve into the event-type message — an event data that reports things that occur instead of describing things that exist. It is crucial to comprehend as companies like Google have amassed a vast fortune by implementing event data, such as clicks and impressions. This data type has created a whole new world of possibilities as its implementation extends the scope and capabilities of the software.
Messaging System
To understand messaging, consider the telephone system. A telephone call is a synchronous form of communication because the caller can only communicate with the receiver if the receiver is available at the time the caller places the call.
On the other hand, with voice mail, when the receiver does not answer, the caller can leave a message. This means the receiver can listen to the messages queued in the receiver’s mailbox whenever the receiver is available.
Voice mail bundles (at least part of) a phone call into a message and queues it for later consumption; this is how messaging works[1].
Let’s go over the parts of messaging system[2]:
Messaging is a technology that enables high-speed, asynchronous, program-to-program communication with reliable delivery. Programs communicate by sending packets of data called messages to each other. The messages and channels model of messaging is a great abstraction and a good way to design a service’s asynchronous API.
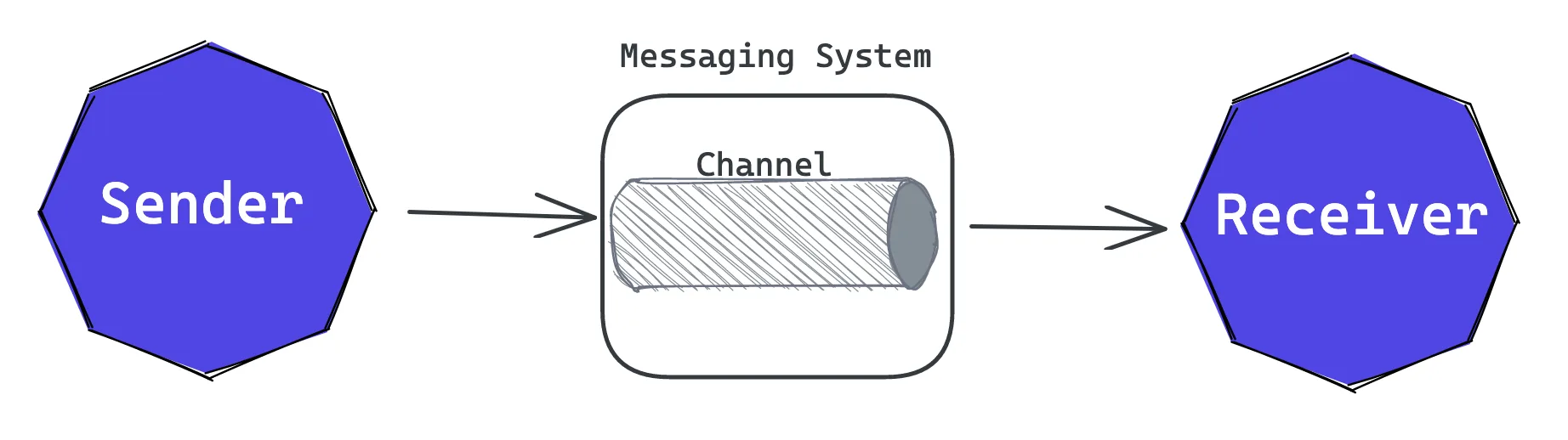
Channels are logical pathways that connect the programs and convey messages. It is the virtual pipe that connects a sender to a receiver. A channel behaves like a collection or array of messages, but one that is magically shared across multiple computers and can be used concurrently by multiple applications. It is an abstraction of the messaging infrastructure. Messages are exchanged over channels. Channel has different names depending on the messaging system. For example, while it is called a topic in Kafka, on the other hand, it is called a queue in RabbitMQ.
A sender or producer is a program that sends a message by writing the message to a channel.
A receiver or consumer is a program that receives a message by reading (and deleting) it from a channel.
A message is simply some sort of data structure—such as a string, a byte array, a record, or an object. It can be interpreted simply as data, as the description of a command to be invoked on the receiver, or as the description of an event that occurred in the sender. A message actually contains two parts, a header, and a body.
The header contains meta-information about the message—who sent it, where it’s going, etc.; the messaging system uses this information and is mostly (but not always) ignored by the applications using the messages.
The body contains the data being transmitted and is ignored by the messaging system. In conversation, when an application developer who is using messaging talks about a message, the developer usually refers to the data in the body of the message.
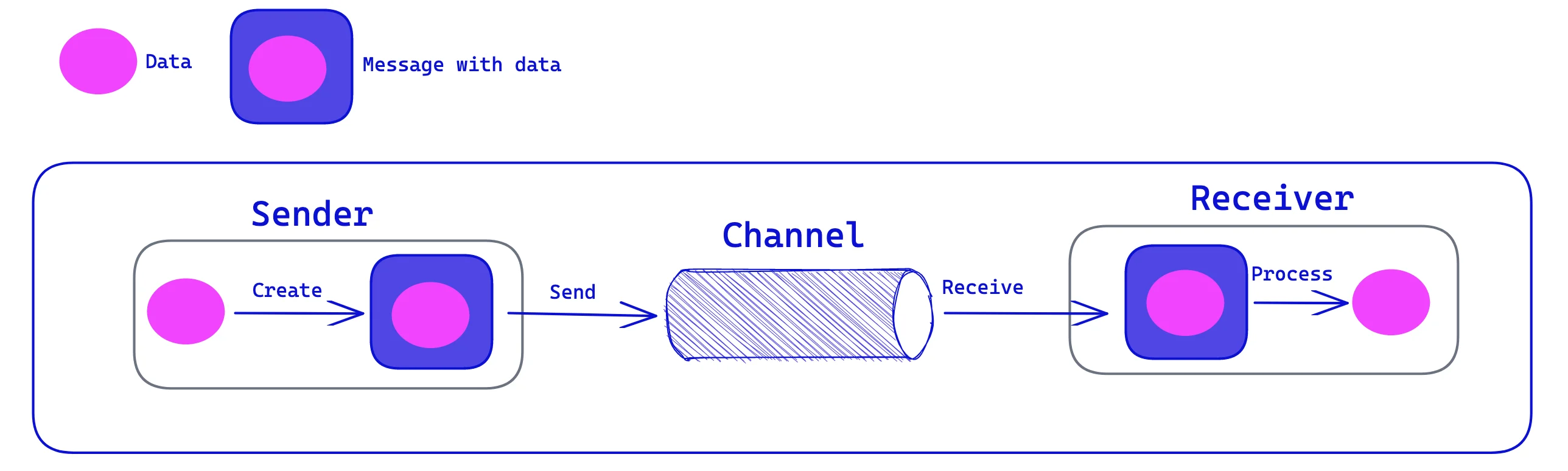
Why not simply deliver the data to the receiver?
By wrapping the data as a message, the applications delegate to the messaging system the responsibility of delivering the data. Because the data is wrapped as an atomic message, delivery can be retried until it succeeds, and the receiver can be assured of reliably receiving exactly one copy of the data.
However, while delivering data, nothing is random. Everything should be specific:
Particular Message Type: A sender application just does not randomly send messages, while other receiver applications just consume whatever message they run across. Rather, the sender knows what sort of information it sends, and the receiver consumes a particular sort of information they can use. Therefore, the messaging system isn't a big bucket that applications throw information into and pull information out of. It's a set of connections that enable applications to communicate by transmitting information in predetermined, predictable ways[1].
Particular Message Channel: When a sender has information to communicate, it doesn’t just fling information into the messaging system, and it adds the information to a particular Message Channel. On the other hand, the receiver doesn’t just pick up at random from messaging system; it consumes the information from a particular Message Channel.
Retrieving Related Info: On the other hand, the receiver retrieves the related info. This is why messaging systems have different Message Channels for different types of information the application wants to communicate.
To sum up, when a sender sends the message, it doesn’t randomly add the info to any channel available. It sends the message to a channel whose specific purpose is to communicate that sort of message. Likewise, an application that wants to receive particular information doesn't pull info off some random channel; it selects what channel to get information from based on what type of the information it wants.
However, there is another important question: Why is messaging system needed?
Basically, we aim to move data from one computer to another. However, the network which connects these two computers is unreliable.
Just because one application is ready to send a communication does not mean the other application is ready to receive it. Even if both applications are ready, the network may not work or fail to transmit the data properly. A messaging system overcomes these limitations by repeatedly trying to transmit the message until it succeeds[3].
Advantages of Messaging System
Let’s look more closely at some benefits of a messaging system:
Asynchronous Communication
Messaging systems allow asynchronous communication where the sender can send a message without waiting for the receiver to process it. The sender is not even required to wait for the messaging system to deliver the message. This feature enables the sender to perform other tasks while the message is transmitted in the background. If an acknowledgment is needed or the sender requires subsequent message delivery, a callback mechanism notifies the sender of the delivery.
Variable Timing
In synchronous communication, the caller has to wait until the recipient finishes processing a call before receiving a response. Asynchronous communication allows the sender to send messages to the recipient at its own pace, without the need to wait for one another. This capability increases the throughput of both applications by avoiding wastage of time in waiting for each other.
Non-Blocking
Asynchronous communication avoids blocking the sender when waiting for the recipient to perform the required task. This feature is essential because waiting for the recipient can block several threads, causing a shortage of available threads to perform actual work. With callbacks, most threads can remain available for other tasks.
Decoupling
Messaging systems offer decoupling, enabling messages to transform in transit without either the sender or recipient knowing about it. Broadcast messages to multiple recipients are possible due to decoupling. This feature provides the option to choose several potential recipients, resulting in an efficient and scalable mode of communication.
Reliable
Messaging systems enable reliable communication by allowing two applications to communicate asynchronously, ensuring one application does not need to run at the same time as the other. If the network receiver is not working as expected, the messaging system can automatically retry the transmission. This autonomous retry feature relieves the sender and recipient of the burden of worrying about transmission details.
However, as you know, nothing is a silver bullet. It's crucial to bear in mind that despite these benefits, messaging systems might not always be the perfect solution for every use case.
What Are the Main Challenges of Messaging Systems?
Complex Programming Model
Messaging systems require mechanisms to send and handle messages, increasing the system's infrastructure complexity. Classifying the flow of messages is crucial, but it can be challenging to troubleshoot and monitor these systems. Instead of coding the application logic in one central point that invokes other methods, event handlers should be separated and organized for messages to respond effectively.
If messaging systems are not implemented appropriately, it can lead to performance issues, like poor or unpredictable latency and high-bandwidth consumption, increasing uncertainties when designing, building, and scaling real-time features.
Sequence Issues
Although message channels guarantee the delivery of messages, it does not guarantee when the recipient receives the message.
After deciding on the messaging system, one needs to decide whether to share data with specific applications or any applications interested in the data. If you want to share data with one application, use a Point-to-Point Channel. Conversely, if you have multiple receivers and want them all to receive the data, use a Publish-Subscribe Channel. When sending data in this way, the channel replicates the data for each recipient.
Publish-Subscribe Model
Before continuing, learning what the event is and how it differentiates from the message will be beneficial.
What Is an Event?
It is an occurrence that has happened in the application. The event itself is in the past and an immutable fact. Some examples of events are customers signing up for your services, the payment received for orders, or failed authentication attempts for an account.
The important point is subscribers have yet to learn what caused the production of these events. They don't care about causes but only events themselves.
Events can be used in different patterns in event-based applications[4]
Event Notification: A notification event typically carries the absolute minimum state, perhaps just the identifier(ID) of an entity or the exact time of occurrence of their payload. Subscribers notified of that event may take action like recording or calling the originating component to fetch additional information about the event.
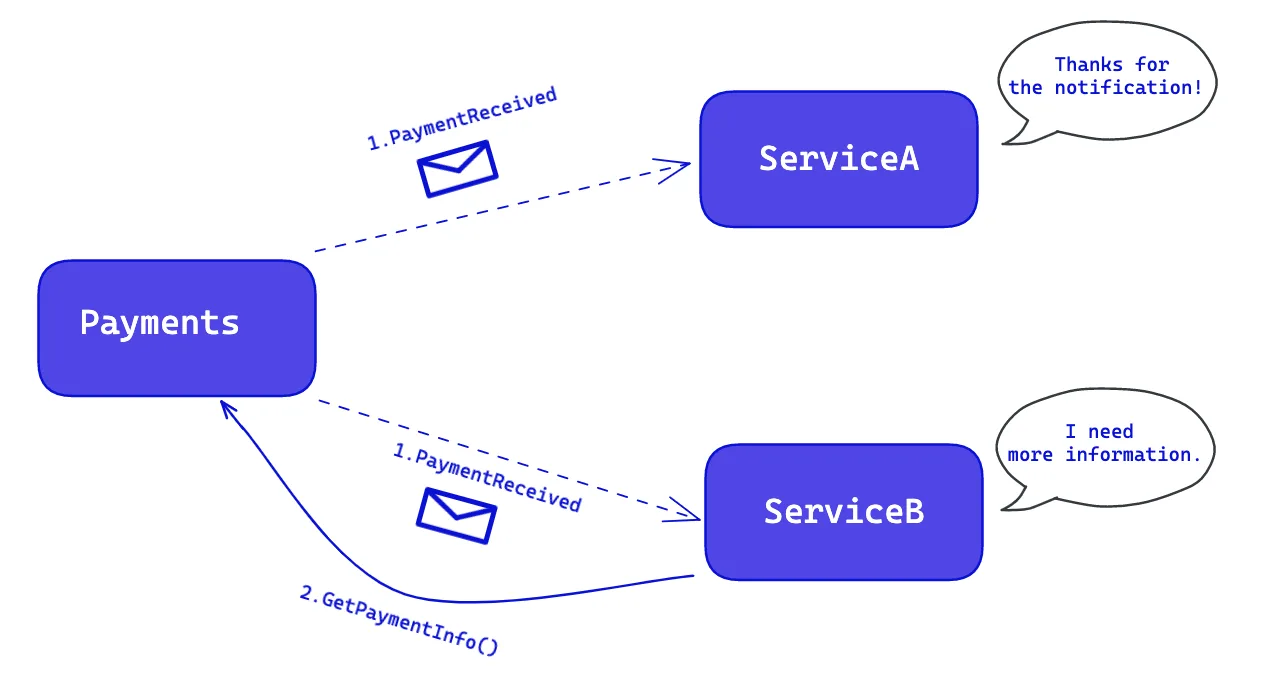
As you can see, ServiceA and ServiceB subscribe to the PaymentCreated event. While ServiceA is satisfied with the information located in the event, ServiceB requires additional information and must make a call back to the Payments service to fetch it.
Event-Carried State Transfer: Event-carried state transfer is an asynchronous cousin to representational state transfer (REST). Unlike the on-demand pull model of REST, the event-carried state transfer push model, whose data changes to be consumed by any subscribers they might be interested.
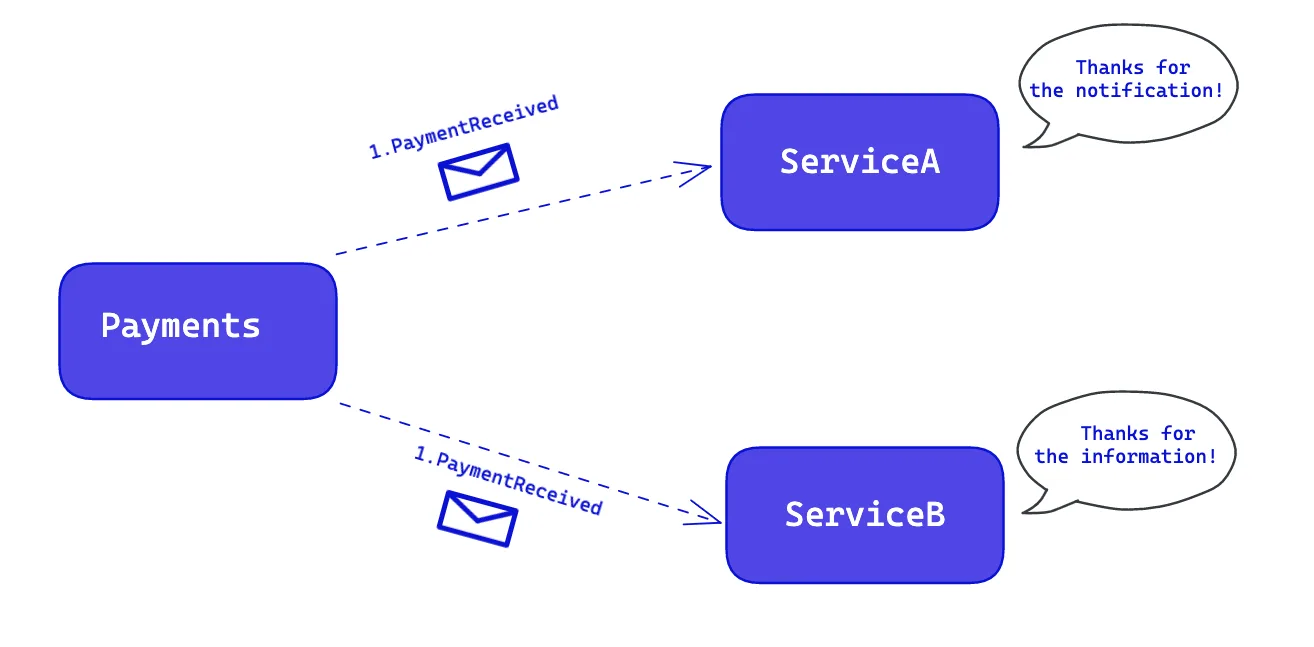
Here, we have some additional information to provide more detailed data. In that model, while ServiceA can be notified for PaymentReceived Event, ServiceB can get what information it needs after being notified. Now, the PaymentReceived event contains everything ServiceB requires.
Event Sourcing: Instead of capturing changes as irreversible modifications to a single record, those changes are stored as events. These changes or streams of events can be read and processed to recreate the final state of an entity when it is needed again.
What Is the Difference Between a Message and an Event?
Before continuing, it is crucial to understand the difference between message and event. You can use events to notify something has occurred within your application. While an event is a message, the message is not always an event. A message is a container with a payload, which can also be an event and can have some additional information in the form of key-value pairs [5]
There are two types of messages[6]:
Event: A message describing a change that has already happened
Command: A message describing an operation that has to be carried out
You can check our microservices orchestration article to learn more about the difference between event and command.
What Is Publish-Subscribe Pattern?
The publish-subscribe pattern is a messaging pattern that allows different services in a system to communicate in a decoupled manner.
The publish-subscribe model's fundamental semantic feature lies in how messages flow from publishers to subscribers. In this model, publishers do not directly target subscribers. Instead, subscribers express their interest by issuing subscriptions for specific messages. Subscribers express their interest independently in the notifications they seek, independent of the publishers that produce them. Once established, subscribers are asynchronously notified of all notifications submitted by any publisher that matches their subscription.
Asynchronous communication is key in this model, ensuring that subscribers don’t wait for notifications to arrive and can perform concurrent operations instead. This makes it possible to handle numerous notifications without worrying about potential blockage, making the publish-subscribe model an efficient solution for information-driven applications.
To avoid the obligation that each publisher must have to know all the subscriptions for each possible subscriber, there is a logical intermediary between publishers and subscribers, known as pub/sub service[7]:
Stores all the subscriptions associated with respective subscribers
Receives all the notifications from publishers
Dispatches all the published notifications to correct subscribers
Therefore, publishers and subscribers exchange information without directly knowing each other. This anonymity is one of the main features of the publish-subscribe model.
In short, this model is an anonymous, many-to-many, asynchronous communication paradigm where multiple producers may send information to many receivers. In that design, publishers and subscribers do not have to know each other, and this will be an advantage when the system grows because they need to communicate with just pub/sub service.
As mentioned, the publish-subscribe model enables applications to communicate asynchronously by using channels. The channel delivers every event to every subscriber.
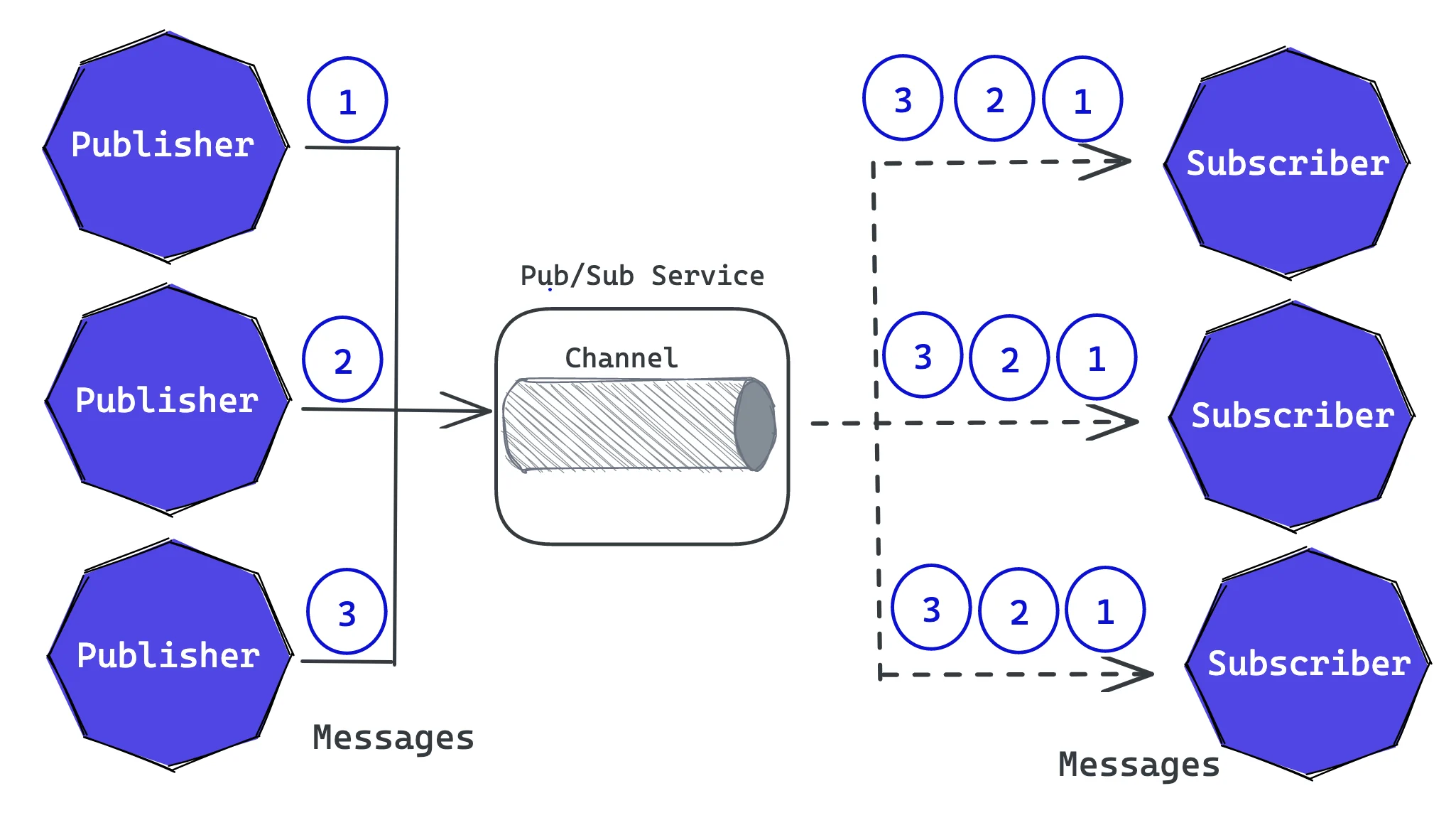
The publish-subscribe pattern utilizes channels to distribute events from publishers to subscribers. Instead of directly targeting specific receivers, publishers send messages to the channel, unaware of the interested subscribers. The pub/sub service ensures that each subscriber receives all related incoming messages, reducing network traffic and improving system performance.
The channel, which acts as the hero of this model, allows multiple publishers to submit messages, which are then published to all interested subscribers. Each subscriber consumes the message once, and it disappears from the channel, ensuring that each subscriber receives all relevant messages.
The decoupling feature of this model is evident since subscribers express their interest in specific events, and publishers are unaware of them. This decoupling provides a flexible and scalable way for system components to communicate. As a result, routing messages can be changed with ease without requiring any alterations to the publisher or subscriber applications.
Therefore, in Publish-Subscribe Model, decoupling can be decomposed along the three dimensions[8]:
Space Decoupling: The interacting parties do not need to know each other. Basically, the publishers publish events through an event service, and the subscribers consume these events indirectly through channels in the event service. The Publishers do not usually know how many of these subscribers are participating in the interaction. Similarly, subscribers do not know how many of these publishers are participating in the interaction.
Time Decoupling: The interaction parties do not need to be actively participating in the interaction at the same time. The publisher might publish some events while the subscriber is disconnected. Vice versa, the subscriber might get notified about the occurrence of some event while the original publisher of the event disconnected.
Synchronization Decoupling: Publishers are not blocked while producing events, and subscribers can get asynchronously notified through callback about the occurrence of an event while performing some concurrent activity.
Decoupling between publishers and subscribers increases scalability by removing explicit dependencies.
Example Use Cases
The publish-subscribe pattern can help to build efficient systems for different use cases, such as:
Broadcasting Notifications:
By using the publish-subscribe pattern, large-scale systems like Twitter can notify all interested subscribers of specific hashtags instead of a single user or application. This also applies to social media platforms, where users can follow each other and receive real-time updates on their activities without the need to continuously poll for updates or manually check each other's profiles.
Stock Trading System:
In a stock trading system, publishers can publish stock price updates to a channel, whereas different components can subscribe to the channel to receive the latest price updates without needing to know about each other's existence. This enables the system to update itself in real-time, minimizing latency, and reducing traffic on the system.
The publish-subscribe pattern is useful for building flexible and scalable systems that enable components to function independently, communicate asynchronously, and receive relevant updates without overburdening the system.
The Bottom Line
The publish-subscribe pattern is a well-known and robust messaging design for developers creating distributed solutions in wide-area environments. This model enables efficient, reliable, and scalable information diffusion as of today.
While distributed systems like client-server that depend on synchronous request-response communication were suitable for traditional applications, they are not useful for information-driven applications such as news delivery, stock quotes, and air traffic control. The publish-subscribe model overcomes this hurdle by allowing indirect and asynchronous communication, reducing the coupling between publishers and subscribers.
With this design, no one gets blocked, and applications can handle several requests without delays.
Download the best JavaScript frameworks guide to answer the 'which JavaScript framework to use for your next project?'