- MACH,
- Composable Architecture
Monolithic vs. Microservices Architecture: Everything You Need to Know in 2024

Have you ever heard of ‘the cargo cult mentality?’
This is basically assuming that ‘if this big and famous company uses that technology and it’s good for them, we can use that in our company, and also this will be good for our company.’
Designing a system as microservices just because everyone else is doing that is not a logical idea. As Sam Newman mentioned in his book Monolith to Microservices, you should be thinking of migrating to a microservice architecture in order to achieve something that you can’t currently achieve with your existing system architecture. However, using the right tool for a specific job should be considered with tradeoffs. Don’t try to find the best design in software architecture; instead, strive for the least bad combination of trade-offs[1].
When you’re doing a tradeoff to choosing microservice or monolith architecture, you should not forget that it is not only a technical decision but also an organizational decision. Your teams need to be suitable to implement the architecture you have chosen.
Here, in this comprehensive guide, you’ll read everything you need to know about monolithic architectures, microservices architecture, microservices vs. monoliths, and how and when to choose which one.
Monolithic Architecture
When all functionality in a system has to be deployed together, we consider it a monolith[2]. Monolithic architecture means all of the code is deployed as a single process.
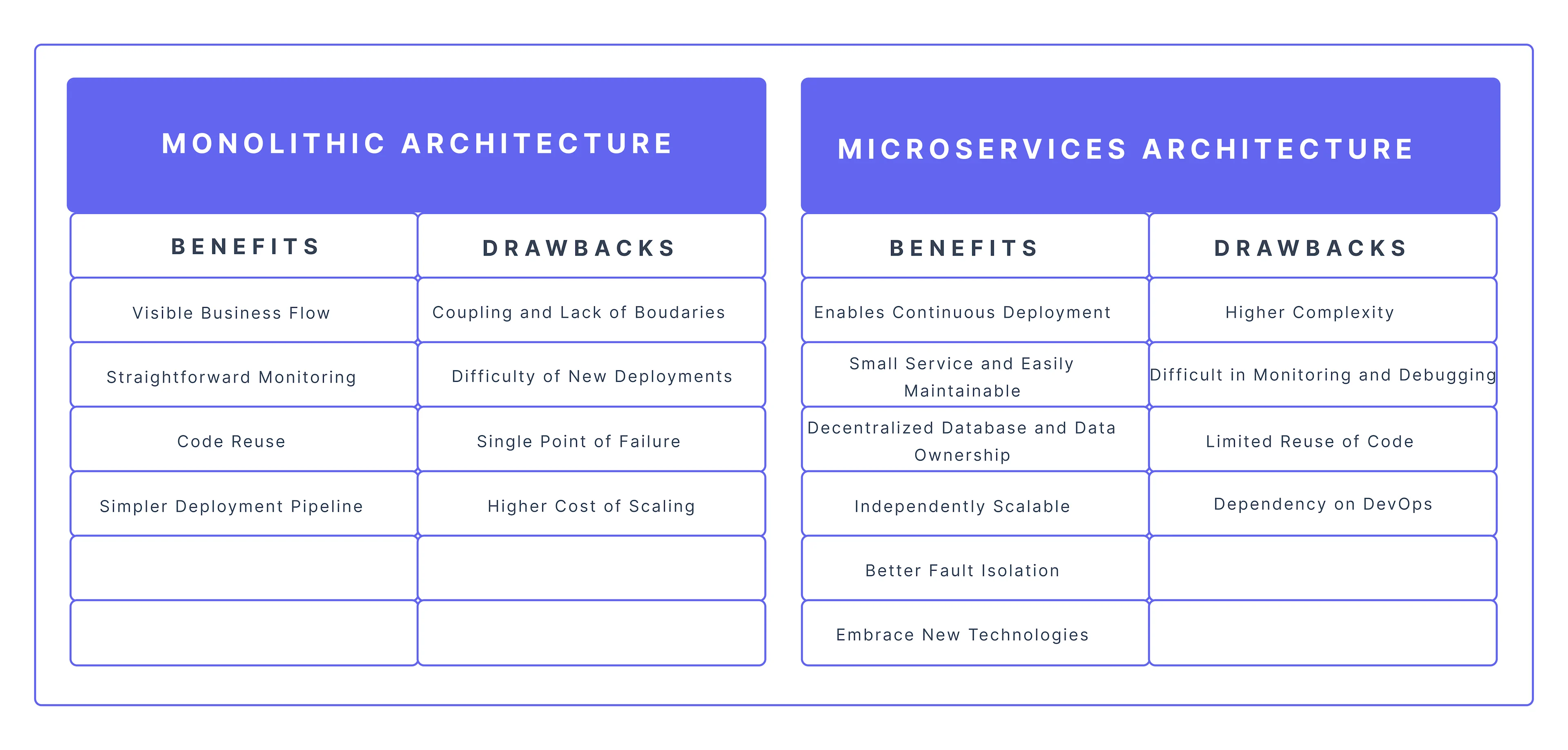
Just like everything in life, monolithic architectures also have their benefits and drawbacks.
The Benefits of a Monolithic Architecture
Visible Business Flow
Monolithic architecture provides developers to maintain a single application with one codebase. It is built as a single unit. This one codebase makes it easier to see the impact of new developments. In this way, you can understand whether new features fit into the overall flow of the application and inspect the end-to-end flow quickly.
Straightforward Monitoring
Monitoring a monolith is straightforward since it is only one application. There is a reduced number of machines to monitor, and the logs are trivial to fetch. Troubleshooting an issue is also easier since the scope is reduced to one application[3].
You do not need to be interested in complicated communication ways (like asynchronous) between services. For example, you can have difficulty inspecting end-to-end flow quickly in microservices based on event-driven architecture because of ****asynchronous interaction between them. In this architecture, you need to understand the flow of events between each service to see the big picture. While each microservices requires a whole different strategy for monitoring, monolith provides straightforward **monitoring.
Code Reuse
Another advantage is reusability. In the monolithic architecture, since all the code resides within the application, it is easy to reuse and build on top of existing functionality[4].
Simpler Deployment Pipeline
Because there is only one application, the deployment pipeline needs to account only for that application’s needs[5]. On the other hand, in a microservice architecture, you need to deploy each microservice that need various configuration because of different needs. Your pipeline can have lesser or larger circles depending on the environment’s diversity comparing monolith architecture. The deployment topology is often much simpler (and cheaper) with a monolith than with a microservices architecture[6].
Because of these advantages, many startups start their journey with a monolithic architecture. Because of limited funding, they give attention to fitting their products with the customer base as soon as possible. They focus on achieving their initial success.
Microservices are a great way of solving the sorts of problems mentioned above you’ll get once you have initial success as an organization.
The Drawbacks of Monolith Architecture
In this section, we will discuss the usual problems of monoliths that can limit business growth. You should understand whether you’re in the hole or not by considering these drawbacks.
Coupling and Lack of Boundaries
As mentioned before, monoliths can become unendurably complex (big balls of mud) and coupled.
All functionalities are inside in single application.
Therefore, there is always a risk of compromising each domain’s boundaries. A single change in monolithic architecture might affect several parts of the system and even down the system.
While your application is growing, it becomes a nightmare to maintain and add new features to your codebase.
The Difficulty of New Deployments
In the software world, your codebase should remain easy to maintain and extendable. You need to easily develop new features and see their effect on the whole codebase.
While it is easy to monitor and debug its effect in one codebase in monolith architectures, the release cycle is usually longer and larger than in a microservice architecture. Even if a company adopts continuous delivery to deliver useful and working software to users as quickly as possible, it will take a considerable amount of time because the whole application must be validated and deployed, which requires a gigantic test suite. This means although you agree small changes make the deployment more controllable and enable fast feedback, it will not be easier to continuously add a new small feature to monolith applications than microservice.
Thus, businesses that rely on monoliths don’t deploy that often (e.g., every day) due to the risk since you always deploy the whole application. Not deploying that often accumulates features, and it is harder to have a continuous delivery mindset. That alone is a common argument for moving away from a monolith[7].
Single Point of Failure
In addition, the risk of deploying monolith is that you can make your whole application down with any change. Even if you change a code in a less critical part of the application, it can affect the whole application.
Higher Cost of Scaling
Large monolith architectures are both difficult and expensive to scale because you need to scale the whole application.
Scaling in monolith requires scaling the entire application rather than parts of it. However, most of the time, only a single or a part of the modules need scaling. Because the modules are bound together in a single application — you must scale the whole application.
You can scale monoliths by installing several instances of that application behind a load balancer. The key point here that being ready to deal with many concurrent requests.
It sounds good, right?
What about a monolith database?
If you want to scale your database, things become more difficult. The only way to scale a database is vertical scaling, and this means pushing up the cost further. However, in a microservices-based architecture, every microservice should have its own database, which provides a more scalable distribution of the data. Therefore, it is possible to scale databases that need scaling horizontally.
By using a microservice approach, it is possible to scale only the part of the architecture that needs scaling and leave the remaining parts with minimal resources, optimizing costs and resources[8].
Microservices Architecture
Microservices architecture enables to develop a single application as a bunch of small services which have their own process and communicate with each other with lightweight mechanisms. These services can be written in different languages, and they can use different data storage technologies. They can also be managed by different teams.
Let's look at the benefits and drawbacks of this architecture.
The Benefits of Microservices and the Microservices Architecture
Enables Continuous Deployment
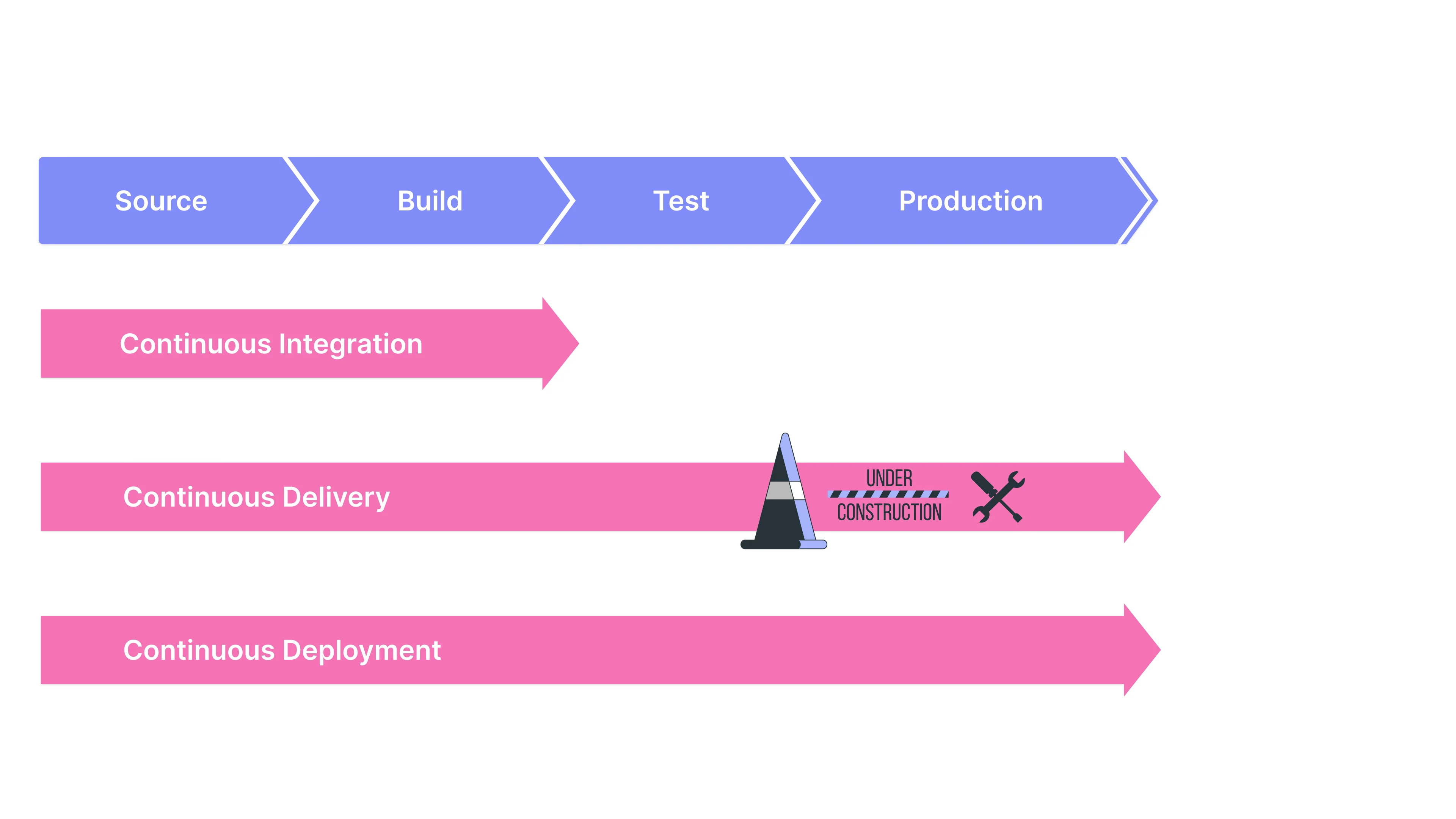
The most important benefit of microservice architecture is that it enables independent and continuous deployment of large, complex applications. There are three ways to implement continuous deployment in a microservice architecture:
Automating Testing
Following the motto of Extreme Programming — if it hurts, do it more often — the logical extreme is to deploy every change that passes your automated tests to production.
Automated tests are an essential part of continuous deployment. The idea behind CD is simply to automate the development circle until the last stage: deployment to production. If your code passes all automated tests, it gets deployed to production automatically. However, it is important to write tests covering your entire application not to cause any breaks.
Independent Deployability
Before discussing independent deployability, we need to define loose coupling first.
Coupling is a measure of how much two components know about and depends on one another[9]. When you hear higher coupling, this means stronger dependency.
On the other hand, loose coupling means different components know as little as necessary about each other. When there is no coupling between components, it means each component is unaware of the other’s existence. This is what you desire in a microservice architecture.
Changes in one service will hardly affect the whole application, thanks to decoupling. Therefore, you can easily deploy that service independently.
If the changes are small, it’s much easier to detect and fix possible bugs.
Smaller releases make for less risk. Thanks to small changes, you can easily find what is wrong and ways to fix it or roll back.
The core idea behind CD is finding ways to reduce the size of the release. CD approach provides you to get fast feedback and release your product whenever you want (release-on-demand). In every tiny change, you deploy your product frequently to get fast feedback.
In software, when something is painful, the way to reduce the pain is to do it more frequently, not less[10]. Herewith, you can catch defects earlier, and it becomes cheaper to fix them. You bring the pain forward with this practice and prevent possible bugs in the future as far as possible.
These practices make it much easier to deploy changes frequently into production and reduce the time to market by enabling the business to react to feedback from customers rapidly.
However, you need to remember: “If your microservices must be deployed as a complete set in a specific order, please put them back in a monolith and save yourself some pain.[11]”
Autonomous Teams and Development Organization & Organic Relationship
Instead of changing and maintaining code in a single application, teams can develop their services autonomously. Because of decoupled nature of microservices, each team can develop, deploy, and scale their services without coordinating with other teams. In a small team, decisions can be made quicker by the people who closely work on these products. Therefore, they don’t have to wait weeks for their pull request to be approved.
During the development process, they agreed upon conditions that could affect their services. Once they need to agree on how to reflect new features in other services, then they can develop their microservices in parallel.
What’s more, the development organization is much more scalable. You grow the organization by adding teams. If a single team becomes too large, you split it and its associated service or services. Because the teams are loosely coupled, you avoid the communication overhead of a large team. As a result, you can add people without impacting productivity[12].
In addition, microservices architecture provides a personal relationship between service developers and their users. The microservice approach support that a team should own a product over its full lifetime. As mentioned, development teams take full responsibility for the software in production, and its smaller granular structure makes it easy to do that. Developers observe and maintain their software from the beginning in an easier way. This causes a direct organic relationship between users and developers.
Due to these points, employee satisfaction is higher because more time is spent delivering valuable features instead of fighting fires[13].
Small Service & Easily Maintainable
The smaller the microservice, the easier it can be developed quicker (agile), iterated on quicker (lean), and deployed more frequently (continuous delivery). But on the modeling side, it is important to avoid creating services that are “too small.”[14]
When your service is small, the code is easier for developers to understand and maintain it. Each microservice can start a lot faster than a large monolith does. This makes developers more productive and speeds up deployment time.
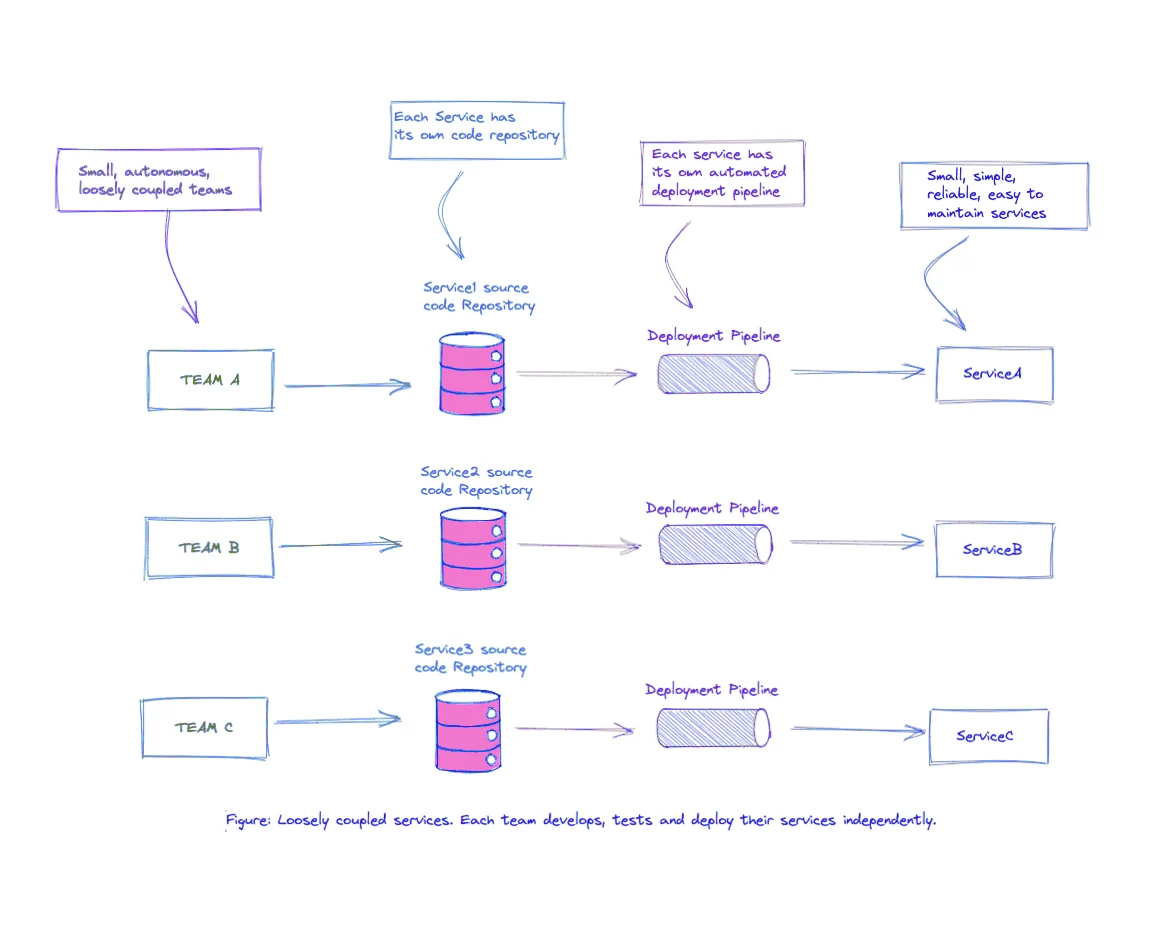
Decentralized Database & Data Ownership
In the traditional approach, there’s a single database shared across all services. Even if it looks simpler and seems to enable the reuse of entities in different subsystems to make everything consistent. However, in the end, you can have huge tables that include attributes and columns that aren’t needed in most cases. In addition, your transaction time to get data from the database can increase because of the cost of the join functions.
One of the important points in the microservice architecture is that each microservice must own its domain data and logic. The general rule of thumb for data ownership is that the service that performs write operations to a table is the owner of that table[15]. After migrating microservices, you must determine which services own what data.
Microservices architecture decentralizes their decisions about both conceptual models and also data storage. Therefore, each microservice should have its own database, which stores the data they need. This architecture prefers letting each service manage its own database, either in different instances of the same database technology or entirely different database systems[16]. In this way, your services are able to choose the most appropriate data store for their use case.
With the decentralized database, you encapsulate the data of each service. It ensures that the microservices are loosely coupled and can evolve independently of one another. If multiple services were accessing the same data, schema updates would require coordinated updates to all the services. This would break the microservice lifecycle autonomy[17].
If your service wants to access data stored by another service, then it should go and ask that service for the data it needs. You can get data from other microservices without accessing their data stores directly. Thus, you can decide which data will be shared or hidden.
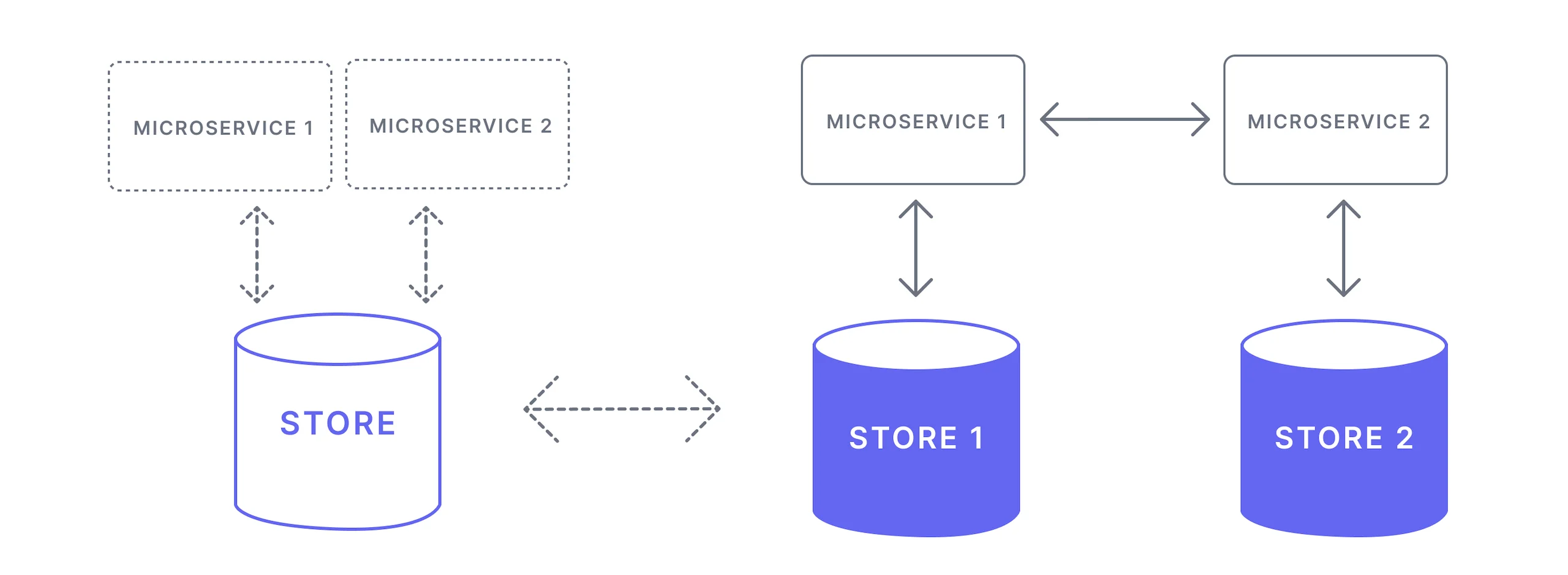
In this way, each microservice has as less as possible knowledge about other microservices, which increases loose coupling. Thus, in the microservice architecture, don’t share databases unless you really have to[18].
Independently Scalable
Thanks to loose coupling and independent deployability in a microservice architecture, you can perform selective or on-demand scaling. If one microservice experience a high load and have difficulty handling all request, you can re-deploy or move that microservice to an environment with more resources without having to scale up hardware capacity for the entire, typically large, enterprise system[19].
Better Fault Isolation
As mentioned before, a single error in monolith architecture has the potential to down the whole system. You need to avoid this in your microservice architecture because you want to design your system as available as possible.
A microservice ecosystem is going to fail at some point or the other, and hence you need to learn to embrace failures. Don’t design systems with the assumption that it’s going to be sunny throughout the year. Be realistic and account for the chances of having rain, snow, thunderstorms, and other adverse conditions. In short, design your microservices with failure in mind. Things don’t go as planned always, and you need to be prepared for the worst-case scenario.[20]
Your architecture can contain a large number of microservices. These microservices communicate with each other via the network to carry out their requirements. If the number of interactions increases between your services, the chance of failure will also increase. Therefore, you need to design your microservices as fault-tolerant as possible.
You need to ensure that one failed service doesn’t make fail the whole system.
If you design microservice architecture by considering these issues, microservices tend to be more fault-tolerant than monolithic applications. This is because you have many decoupled and autonomous services instead of a single application.
In some very famous companies like Google, Netflix, etc., failure is simulated by systems by writing programs that cause failure and running them in production on daily bases in Netflix, Google simulates large-scale disasters as part of its annual DiRT(Disaster Recovery Test) exercises[21].

Let’s look at some programs, Simian Army, written by Netflix for simulation[22]:
Chaos Monkey turns off random machines during certain hours of the day.
The Chaos Gorilla is used to take out an entire availability center (the AWS equivalent of a data center).
Latency Monkey simulates slow network connectivity between machines.
What do they provide?
Knowing that these simulated problems can and will happen in production means that the developers who create the systems really have to be prepared for it.
The important point is that you need to embrace and trigger possible failure and build your software to handle these problems. It’s really important to learn lessons from these simulated failures to enhance your system to scale better.
It is important to know there is always a chance of something going wrong. The fact that your system is now spread across multiple machines (which can and will fail) across a network (which will be unreliable) can actually make your system more vulnerable, not less. Preparing yourselves for the sorts of failure that happen with more distributed architectures is pretty important[23].
Embrace New Technologies
The microservices architecture eliminates any long-term commitment to the technology stack[24]. Because each service is autonomous, the developers are free to use any language which best suited for the business needs.
The Drawbacks of Microservices
No technology is a silver bullet. Microservices architecture has a number of significant drawbacks.
Higher Complexity
While designing microservice architecture, developers need to deal with additional complexity.
Instead of method calls in monoliths, microservices must use an interprocess communication mechanism. This means sending and receiving calls over networks needs more time than calls inside in monoliths.
Microservices can use synchronous request/response-based communication mechanisms, such as HTTP-based REST or gRPC. Alternatively, they can use asynchronous, message-based communication mechanisms such as AMQP or STOMP.
In synchronous communication, one microservice invokes another microservice by sending a request and expecting a response within a given time frame. Calling service and waiting response from called service block the execution and create implicit dependency on the services that it calls. Therefore, having more synchronous request-response interactions leads to more coupling among microservices.
You may not feel the effect of synchronous dependency because of the existing small number of services. However, when the number of services that communicate with a request-response pattern increase, the latency of execution will increase because of a larger chain of dependent services. If you want to maximize availability, you must minimize the amount of synchronous communication.
As a powerful alternative to the synchronous approach, in asynchronous communication, one microservice communicates with another microservice by sending messages without expecting a response. Here, your two microservices communicate with each other via third-party components such as message brokers or event brokers. This component receives the messages from the source/producer microservice and sends them to the consumer. A consumer consumes the messages that it is interested in via a message broker.
In asynchronous communication, there is no blocking and waiting for a response because your service can continue to do another job. The critical point here is that problems in another service don’t break this service, and when other services are temporarily broken, the calling service might not be able to complete a process completely, but the calling service is not broken itself[25]. Therefore, by using asynchronous messaging, your services become more decoupled and more autonomous.
However, if we look at the downside of asynchronous messaging, it increases the infrastructural complexity of the system because it requires mechanisms to send and handle messages[26]. Designing the flow of domain events becomes essential, and it will be difficult to monitor and debug problems.
In the real world, you can use these communication patterns together simultaneously.
Microservices rely heavily on the network to communicate with each other. This can result in slower response times (network latency) and increased network traffic. In addition, it can be difficult to track down errors that occur when multiple microservices are communicating with each other.
Difficulties in Monitoring and Debugging
Before diving deeper into monitoring, it’s better to define observability and monitoring since these are close concepts:
Observability, in the context of a software application, refers to the ability to understand and explain a system’s state without deploying any new code
[27]. It is a superset of monitoring.
Monitoring refers to the process of becoming aware of the state of a system
[28]. With proper monitoring, you will be able to detect issues before system failure.
Thus, while monitoring is focused exclusively on tracking a system’s health, observability also provides tools to understand and debug the system. For example, monitoring on its own is good at detecting failure symptoms but less so at explaining their root [29].
Failure is rarely predictable, and detecting the exact cause of complex application errors in production is extremely difficult. While you’re developing your application, you try to predict any possible scenarios that could lead your application down and risk data loss. Thus, it is essential to be able to observe and monitor your application to detect failure as immediately as possible.
Observability and monitoring are crucial concepts in the microservice world. In a microservices architecture, there are a lot of services, and it is difficult to detect an error. If you don’t observe and monitor your system well, all the existing murders create killers that cannot be found. You need to be good detectives to find the killer who commits homicide.
Monitoring and debugging a microservice-based application can be difficult because the application is spread out across multiple servers and devices.
Limited Reuse of Code
Microservices also have a limited ability to reuse code.
You need to refresh your perspective towards the important clean code principle: “Don’t Repeat Yourself”
Let’s introduce to you your new friend: WET(write every time or write everything twice).
The critical point of WET is reducing the amount of shared code. Microservices usually prefer to duplicate code rather than reuse it to avoid coupling. Each microservice is small and purpose-built, serve to specific business goals of organizations. This means that they have their own domain, which includes independent business logic.
For example, If you use the same function in your microservices which have different business logic to solve different problems when each microservice evolves independently based on the needs of the business environment, your application will break because of sharing the same function. This function cannot meet the needs of the business logic of both microservices. Reusing code is less useful because it is really hard to deal with every possible use case with the shared function.
Dependency on DevOps
In order to be successful with microservices, organizations need to have a strong DevOps team in place. This is due to the fact DevOps is responsible for deploying and managing microservices.
Without a good DevOps team, it can be difficult to implement and manage a microservice-based application successfully.
Overview of Monolithic vs. Microservices Architecture
Moving from Monolith to Microservices
Have you ever heard of ‘The Law of Holes?’
It simply states that “if you find yourself in a hole, stop digging.”
It can be really great advice to follow when your monolithic application has become unmanageable. You should not implement new features if you have a large and complex monolithic application. If you do that, you’ll make an already complex system more complex.
Thus, your application becomes even larger and more unmanageable. Instead, you can implement new features as services.
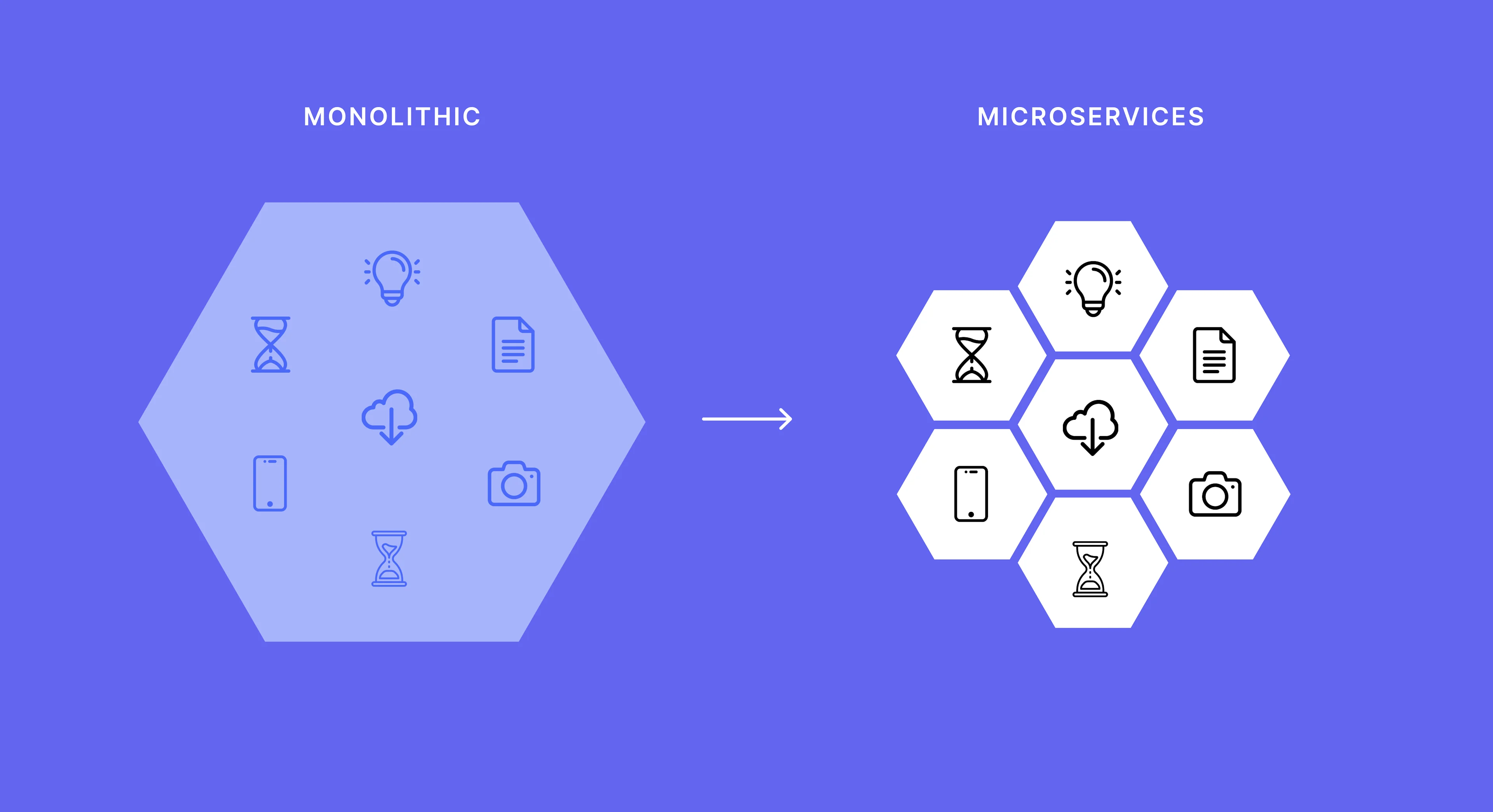
There are some situations you need to consider migrating from monolith to microservices:
Smaller and Fast Releasing
Customers’ and stakeholders’ requests never end.
They always want new features all the time.
You need to develop these changes fast and reliably. In a monolith, architecture is really hard to release new features because the whole application must be validated by a gigantic test suite and deployed.
Smaller releases make for less risk.
If you make a small change, it’s much easier to spot and fix a problem you create. Microservices architecture makes it easy to deploy your application with smaller changes. Imagine that you deploy your microservices every night. This regular and automatic deployment provides a much deeper relationship between your customers and stakeholders because you can quickly answer problems and opportunities. You’re not waiting for a blue moon anymore to deploy your application. Software release should be fast — not cost a lot of money.
Scalability
Your customers are increasing. It is really good for your company’s interests.
However, your monolith system cannot handle all the requests of your customers. It responds to your customers very slowly, and complaints from your customers are increasing. You need to scale your systems. You want to scale your system more cost-effectively way.
With microservices, you can able to scale your services independently. It means you can scale up only services under high load. It also means you can scale down those services that are under less load. This is, in part, why so many companies that build SaaS products adopt microservice architecture. It gives them more control over operational costs.
Embrace New Technology
Monoliths typically limit your technology choices.
You’re fixed to one deployment platform, one operating system, and one type of database.
With a microservices architecture, you get the option to vary these choices for each service. The flexibility of being able to try new technology in a safe way can give you a competitive advantage, both in terms of delivering better results for your customers and in helping keep your developers happy as they get to master new skills[30].
The Bottom Line: When and How to Choose Between a Monolithic and Microservices Application

[Image Source: Vue Storefront]
As mentioned before, startups may start their development with monolithic applications because of limited funding and the desire to achieve their initial success as soon as possible.
In monolithic architectures:
business flow is more visible
you can monitor your monolithic application easily
you can easily detect the problem
And all of these give you a huge advantage in achieving initial success.
Moreover, by enabling code reuse, you can use the same code in different modules. This can help reduce code duplication and increase efficiency. Therefore, you can set up your pipeline easier, which accounts only for one application’s needs.
However, there can be times you should stop digging not to make your hole deeper. When your code becomes huge, and whenever you want to deploy your application, it becomes more painful because of the larger release cycles. This is where you need to consider microservices-based architecture.
It is really important not to allow your application to become a big ball of mud because it creates more risks to down your whole application with one tiny change.
What will you do when your application cannot handle increasing requests?
Do you think about scaling your monolith application?
Sorry, there is bad news for you. It will be more difficult and expensive because you need to scale the whole application rather than part of the modules that need scaling.
Do you still think about migrating your monolith architecture to microservice architecture? Before doing that, you need to make a tradeoff by considering microservice’s benefits and drawbacks.
With microservice architecture, you can deploy your large and complex application independently and continuously.
You will have automated testing, and with every tiny change, you can easily deploy your application if it passes all automated tests. If it will not, you can detect the bug easily because you will get fast feedback.
Remember! Smaller releases make for less risk.
In addition, teams can develop their services autonomously. This provides you you scale your team easily and let them develop, deploy, and scale their services without coordinating with other teams.
Because of the small codebase of each microservice, it is easier to understand the code and maintain it. This makes your teams more productive. Because each microservice has its own database and each microservice can access its own database, your microservices can evolve independently.
In this way, you won’t break microservice lifecycle autonomy. Because of autonomy and independent deployability, you don't need to scale your whole application. It will be an efficient way just to scale services under high loads.
In addition, you have a chance to design your system with better fault isolation. Therefore, you need to ensure that one failed service doesn’t fail the whole system. If you embrace your failures and design a system that can handle these failures, you can see microservice architecture’s most important benefit, which is not allowing your system to go down with a single bug.
You don't no longer need to depend on just single technology. You can develop your microservices with any programming language depending on business needs.
However, again, great power comes with great responsibility. If you decide to develop your application with microservices, you need to do the best you can to handle problems.
Your architecture becomes more complex because you don't have a single codebase anymore. Communication between microservices through the network makes your architecture more complex. You need to have comprehensive knowledge of synchronous and asynchronous communication with their benefits and drawbacks. Because of communication through the network, it can be difficult to track down errors that occur when multiple microservices are communicating with each other. Monitoring your application and debugging these errors become more complicated.
You don't want to give rise to murders and create killers that cannot be found.
In microservices-based architecture, you need to keep your mind that you shouldn’t share your code to prevent coupling between your microservices. Microservices-based architecture needs a strong DevOps team. You need to create pipelines that account for multiple microservices’ needs. This means every microservice has its own release cycle. Your DevOps team is responsible for providing that.
To sum up, when you are building an application, you need to be careful to choose your architecture by considering all benefits and drawbacks mentioned in this comprehensive guide. Making tradeoffs is at the heart of software development.
Don’t forget! There is no silver bullet in this world.
Learn everything you need to know about MACH architecture